用Solr打造定制的搜索引擎
在数据分析、站内搜索等应用中,我们往往需要有自己的搜索服务。Apache Solr(用户包括Instagram、Netflix和Digg)和ElasticSearch(用户包括GitHub、Quora和eBay)就是目前最流行的开源搜索服务器软件,无独有偶,它们都基于用Java语言编写的搜索引擎Apache Lucene。
开始使用Solr
- 确保Java运行时环境已经安装好
- 下载Solr
- 进入解压后目录
- 运行
bin/solr start -c启动Solr云 - 运行
bin/solr create -c 集合名 -s 2 -rf 2创建一个集合,其中-s 2表示集合索引数据分散到两个节点、而-rf 2表示所有索引数据有两个复本 - 回到命令行运行
bin/post -c 集合名 需要索引的文件列表以索引一些你想以后能搜索到的文件 - 在浏览器打开http://localhost:8983/solr/进入控制台
- 从左下方选择刚创建的集合
- 在
Query选项卡中进行查询
搜索引擎的工作方式
设想有一本书(如《电工手册》),我们想知道里面有没有一个词(如“无刷电机”),有的话在哪些段落中。如果这本书没有索引,则我们可能需要把整本书看完才知道,除非十分走运,这个词刚好出现在我们一开始翻的哪几页。对于一本书,还可以勉为其难地这样干,但如果要在整个大型图书馆中这样去找一个词出现在哪些书中则可以认为是不可能的任务。如果这本书有索引,我们只用在索引中找有没有“无刷电机”这个词,由于索引中各个词是排好序的,能够很快地定位它,然后有的话索引就告诉我们这个词在哪页出现。如果希望的话,我们甚至可以通过把图书馆中所有书的索引合并起来。由于图书的物理结构是把位置自然地对应到词,这种把词对应到位置的索引也叫倒排索引。我们要强调的是,建立索引是一次性的,却可以为大大缩短了查询所需的时间。
对于数字数据也是同样道理,我们对需要搜索到的数据做一次索引,然后查询就能基于索引而不是原始数据进行,这样查询可能做到非常快。和图书一样,索引本质上是个映射,把关键词对应到它所在文档的列表。倒排索引有不同的实现方式,例如映射表可以是B+树、分布式散列表或者其它数据结构,文档列表可以用链表、位图或者其它数据结构实现,但这些细节还是留给Lucene的开发者去考虑好了。
建立索引时,需要进行以下工作:
- 获取数据。首先必须确定获取要索引的文档。这在一些比较专门的应用中是比较明显的,这时我们可能已经拥有要索引的全部数据,但有时也可能要人工收集(如首次数字化图书馆馆藏信息时)。在类似Web搜索中,配置爬虫的策略则涉及许多的问题。
- 导入数据。搜索系统把文档看作由一些字段组成,而原始数据可能以各种不同的格式存在,因此经过需要加载、转换和清洗才能使用。导入文档有以下途径:
- 来自文件
- 对于XML、JSON、CSV等格式的文件,它们清晰地给出了结构化数据
- 对于PDF、Microsoft Office、OpenDocument、RTF、HTML、TXT、LOG等格式的文档,还需要一些程序来进行解析并提取出各字段
- 来自数据库
- 来自文件
- 分析各个字段的值,
- 分词。把字段值分解成单词有许多不同方法,如单词满足的正则表达式、分隔符满足的正则表达式、N-Gram。对于欧洲语言,分词相对简单,不论以最长字母序列作为单词还是在空白和标点符号处切分都有不错的效果。但对于中日韩语言,要准确切分并不容易,基于词典的最长前缀切分要求词典不断更新(这也是许多搜索引擎也做输入法收集数据的原因,但每次更新词典后更新索引成本太高,不然又会影响搜索质量),有时干脆把每个字符或N-Gram(如“万里长城永不倒”分成2-Gram“万里”、“里长”、“长城”、“城永”、“永不”、“不倒”)当作单词。
- 过滤。对单词序列往往会进行一些变换,比如:
- 统一大小写。搜索者通常不在乎结果的大小写。
- Unicode规范化。同一字符序列如重音、连写、全半角、繁简等等有不同的表示,需要规范化。
- 词干提取。有的语言中动词有多种时态、名词有多种复数形式,有时会带“’s”之类,而搜索者通常不在乎这些,需要把它们归一化。
- 加入同义词。搜索者通常也希望搜索同义词时结果类同。
- 加入同音词或拼音。搜索者往往会犯拼写错误或者根本不知道一个字怎么写却知道怎么读。
- 去除停用词。去除太常见的词可节省空间。如英文中常去除“a”、“an”、“and”、“are”、“as”、“at”、“be”、“but”、“by”、“for”、“if”、“in”、“into”、“is”、“it”、“no”、“not”、“of”、“on”、“or”、“such”、“that”、“the”、“their”、“then”、“there”、“these”、“they”、“this”、“to”、“was”、“will”、“with”。不过这样下来搜索“To be or not to be”就没有有意义的结果了,所以往往有另一个保护词名单。
- 去掉两侧空白。
- 更新索引。让上一步最后得到词指向文档。不过有的的搜索系统会拒绝与已经索引过的文档高度雷同的文档,这通常是通过增加一个散列值字段来实现的。
在查询时,需要进行以下工作:
- 解析用户的查询。根据搜索语法和语义理解用户的查询,即结果应满足的条件(如
足球 篮球 -网球 site:cctv.cn可能被理解为寻找含有“足球”或“篮球“的文档,它的site字段为“cctv.cn”,其中不能含有”网球”),这还可能需要应用类似于与索引时字段分析的方法。 - 通过倒排索引找出结果集的一个超集(如上例中可能为含“足球”文档集和含“篮球“文档集的并)。
- 过滤,即从上一步结果集中去除不满足整个查询的结果集(如上例中可能要去除含“网球“文档集和site字段不匹配“cctv.cn”的文档集)。
- 对结果排序。当搜索结果很多时,用户一般只会注意到排在最前面的结果,所以排序对搜索质量非常重要。
- 相关度。我们希望与查询最吻合的结果排在最前面。至于相关度的计算有不同方法,为了简单见,我们仅介绍一种基本的方法,基本想法是计算查询中各单词频率与文档中各单词频率的相似性(使用频率而不是频数是因为避免对不同查询都返回几乎什么词都有的长文档),但注意到不同词的重要性是不同的,越罕见的词应该越有区分力。假设索引中有词$k_1,\dots,k_n$,在一个并查询中它们的频率分别为$f_1,\dots,f_n$,在文档中它们的频率分别为$F_1,\dots,F_n$,而在所有文档中它们出现的频率分别为$N_1,\dots,N_n$,则记$q=(\log (1+f_1)\log \frac{1}{N_1},\dots,\log (1+f_n)\log \frac{1}{N_n})$,$d=(\log (1+F_1)\log \frac{1}{N_1},\dots,\log (1+F_n)\log \frac{1}{N_n})$,于是查询与文档的相关系数为$\frac{q\cdot d}{\vert q\vert\vert d\vert}$。其中$q$、$d$中各分量的计算有不同方法,但都是一个跟局部词频有关的因子(TF)和一个与全局词频有关的因子(IDF)之积。由于查询中词一般很少,公式中非零项很少,所以计算可以很快。
- 流行度。基于越多人需要的页面也应该是你会需要页面的信念,流行的结果应该排在前面。
- 入链。基于随机行走模型,用户在进入每个页面后,有一定的概率后退、一定的概率输入一个网址、余下情况则是随机点击页面上的链接,据此可估算用户进入每个页面的概率,这可作为流行度的一个指标,Google当年成名的PageRank算法就在做这事情。
- 浏览数据。点击率、浏览量、收藏量等等都可反映流行度,值得一提的是如果用户跳过排在前面的结果点击后面结果,则对前面结果可能是负面指标。许多搜索引擎厂商也做浏览器和公开DNS服务器的部分原因就是要收集这些数据。
- 字段。对于结构化数据的搜索,根据发布日期、价格等字段排序可能是有意义的。
- 综合评分。通过把多种指标通过某种公式(如加权平均)结合起来得出一个评分可能可比较完整地反映用户偏好,至于公式及其中参数的选取通常要慢慢试错。
- 附加工作。对于一个现代的搜索系统,还往往包含以下功能:
- 搜索建议。建议用户进行另一个查询,这可能基于拼写检查器、关联词(搜索结果中共同出现的其它词)或者协同推荐(其它和你作出过类似查询的人也作了什么查询)
- 分片。建议用户加上过滤条件,如主题、日期范围等等。
- 类似结果。需要时用与某个文档的相关度排序结果,在电子商务网站中常见的“类似产品”就是例子。
- 结果高亮。搜索结果摘要中突出显示出现的搜索关键词,以便让用户理解为什么系统会提供这结果。
- 结果分组。可以根据字段或聚类算法把类似结果放在一起以便用户筛选,例如把来自同一问答类网站(如百度知道或Stackoverflow)结果放在一起,又或把对应一个词不同含义的结果分开(如在“IDE”的结果页把关于“Integrated development environment“和关于”Integrated Drive Electronics”的结果分开)。
- 定制结果。对于特定类型的查询,可能可设计专门的结果,如显示来自维基百科的摘要、加上竞价广告、搜索算式时返回计算结果。
最后提一下一些用于评估搜索系统结果质量的方法:
- 精度与召回率是经典的搜索指标。给定一个搜索需求,精度是指搜索结果中能满足需求的比例,而召回率是指被索引文档中能满足需求的文档中被返回为结果的比例。这两个指标当然是越高越好,但通常精度越高,召回率越低,反之亦然。在极端情形,只要返回所有文档就可以让召回率达到100%。对于不同应用,对这两个指标有不同偏好从而要取不同的平衡点,通常来说Web搜索对精度要求较高,而法律判例搜索则要求高召回率。精度与召回率的不足在于没有考虑排序,还有在文档很多时难以计算(只能借助抽样估计)。
- A/B测试用于比较两个相同目的的搜索系统。一批测试员分别使用两个系统进行搜索任务,然后分辨哪个系统给出的结果更有用。
配置Solr
配置Solr
- Solr全局选项可以在
server/solr/solr.xml中配置。 - 在使用Solr云时ZooKeeper可在
server/solr/zoo.cfg中配置。
我们在这里不会重点介绍部署和维护,所以不展开它们。
配置Solr集合
Solr的每个集合可以进行配置。例如在server/solr/核/core.properties文件中的collection.configName属性指定了所用的配置名(一般在创建集合时选择):
#Written by CorePropertiesLocator
#Sun Apr 15 09:27:42 UTC 2018
numShards=1
collection.configName=fulltext_configs
name=fulltext_shard1_replica_n1
replicaType=NRT
shard=shard1
collection=fulltext
coreNodeName=core_node2
实际的配置在server/solr/configsets/配置名/conf目录中,其中应该至少有solrconfig.xml、managed-schema两个XML文件。
如果正在使用Solr云,则修改配置后需要上传配置,例如:
bin/solr zk upconfig -d fulltext_configs -n 配置名 -z localhost:9983
模式
Solr把文档看作由一些字段组成,每个字段可以有不同的类型,以便Solr作出最贴切的处理。通常模式在managed-schema文件(以前是schema.xml)中指定,在默认配置中它开首形如:
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!--
本例子是用户的推荐起点,它应当保持准确和精简,直接可用。
关于定制本文件的更多信息,参见:
http://lucene.apache.org/solr/guide/documents-fields-and-schema-design.html
性能注记: 本模式包括许多可选的特性,不应用作性能基准。为提升性能应当:
- 对于只需搜索而不需要返回原始值的字段(特别是长字段)尽可能设为 stored="false"
- 对于只需要返回而不需搜索的字段应设为indexed="false"
- 移除所有不必要的copyField标签
- 为了索引大小和搜索性能,对一般文本字段设置"index"为false,用copyField复制到
用于搜索的"text"字段
-->
<schema name="default-config" version="1.6">
<!-- "name"属性是模式只用于展示,version="x.y"是Solr的模式语法版本号,一般不应修改
1.0: multiValued属性不存在,所有字段本质上为multiValued
1.1: multiValued属性被引入,默认为false
1.2: omitTermFreqAndPositions属性被引入,除文本字段外默认为true
1.3: 移除可选字段compress
1.4: autoGeneratePhraseQueries属性被引入,默认为off
1.5: omitNorms对基本字段类型(如int, float, boolean, string)默认为true
1.6: useDocValuesAsStored默认为true.
-->
声明字段
然后是指定文档中有哪些字段,分别对应什么类型。
<!-- 适用于字段的属性:
name: 必备 - 字段名
type: 必备 - 字段类型名,参考fieldTypes节
indexed: 字段应被索引(用于搜索或排序)时为true
stored: 字段应能获取时为true
docValues: 字段应该有文档值时为true。对于分片、分组、排序和函数查询推荐文档值
(Point字段必备)。文档值使索引加载更快、更近实时友好、内存效率更高。
目前只支持字符串字段、UUID字段、点字段,部分字段类型可能还要求单值或不能缺失
multiValued: 一个文档中能有多个同名字段时为true
omitNorms: (专家) 设置为true会忽略字段的范数(从而不能长度归一化和索引时提升
但节省内存),只有全文字段或需要索引时提升的字段需要它。
对于基本 (不分析的) 类型默认忽略范数
termVectors: [false] 设置为true会保存字段的项向量,有利于提升作为
MoreLikeThis相似度字段时的性能
termPositions: 把位置信息保存到项向量,会增加空间开销
termOffsets: 把偏移信息保存到项向量,会增加空间开销
required: 字段是必备的,缺失时抛出错误
default: 增加文档时字段缺失时用来补上的默认值
useDocValuesAsStor: 若启用docValues了,则对fl为*即使stored=false 字段也能返回
large: 在要求字段延迟加载且只在短于512KB时才缓存的话为true,只适用于
stored="true"且multiValued="false"的字段
-->
<!-- 字段名应当由字母、数字或下划线组成,不以数字开始。这目前不是强制的,
但其它字段名可能不会被所有组件原生支持,向后兼容性也没有保证。
同时由下划线开首和结束的名字 (如 _version_) 被保留
-->
<!-- 在这个_default配置集,只预定义了四个字段id, _version_, _text_ 和 _root_
所有其它字段会通过类型猜测和solrconfig.xml声明的"add-unknown-fields-to-the-schema"
更新处理器链声明
注意定义了许多动态字段 - 你可以用它们通过命名约定指定字段类型 - 如下.
警告: 捕获字段 _text_ 会显著增大索引大小,不需要的话移除它及对应的copyField标签
-->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- docValues对long类型默认启用,所以不用索引版本字段 -->
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- 在客户不知道该搜索哪些字段时可以启用它,但索引所有东西两次是昂贵的 -->
<!-- <copyField source="*" dest="_text_"/> -->
<!-- 动态字段容许通过字段名模式对字段约定先于配置
例如: name="*_i" 会匹配所有以 _i 结束的字段名 (如 myid_i, z_i)
限制: 类glob模式的name属性中"*"只能在开始或结束 -->
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pints" indexed="true" stored="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>
<dynamicField name="*_t" type="text_general" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="booleans" indexed="true" stored="true"/>
<dynamicField name="*_f" type="pfloat" indexed="true" stored="true"/>
<dynamicField name="*_fs" type="pfloats" indexed="true" stored="true"/>
<dynamicField name="*_d" type="pdouble" indexed="true" stored="true"/>
<dynamicField name="*_ds" type="pdoubles" indexed="true" stored="true"/>
<!-- 用于数据驱动模式的类型,为每个文本字段增加一个字符串副本 -->
<dynamicField name="*_str" type="strings" stored="false" docValues="true" indexed="false" />
<dynamicField name="*_dt" type="pdate" indexed="true" stored="true"/>
<dynamicField name="*_dts" type="pdate" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_p" type="location" indexed="true" stored="true"/>
<dynamicField name="*_srpt" type="location_rpt" indexed="true" stored="true"/>
<!-- 负载动态字段 -->
<dynamicField name="*_dpf" type="delimited_payloads_float" indexed="true" stored="true"/>
<dynamicField name="*_dpi" type="delimited_payloads_int" indexed="true" stored="true"/>
<dynamicField name="*_dps" type="delimited_payloads_string" indexed="true" stored="true"/>
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>
<!-- 用于强制文档惟一性的字段,除非标记为 required="false",否则是必备的 -->
<uniqueKey>id</uniqueKey>
<!-- copyField 在文档增加到索引时把一个字段复制到另一个,以便用不同方式索引相同数据
或者把多个字段复制到一个以便更容易或快捷的搜索
<copyField source="sourceFieldName" dest="destinationFieldName"/>
-->
对于不同应用,需要声明不同的字段,例如一个全文搜索PDF、HTML、Microsoft Office、Open Document等非结构化格式的文档的搜索系统可能需要如下声明字段:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
<field name="content_type" type="string" indexed="true" stored="true"/>
<field name="language" type="string" indexed="true" stored="true"/>
<field name="url" type="string" indexed="true" stored="true"/>
<field name="date" type="pdates" indexed="true" stored="true"/>
<field name="keywords" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="subject" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="description" type="text_general" indexed="true" stored="true"/>
<field name="author" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="title" type="text_general" indexed="true" stored="true"/>
<field name="content" type="text_general" indexed="true" stored="true"/>
<copyField source="content_type" dest="_text_"/>
<copyField source="language" dest="_text_"/>
<copyField source="url" dest="_text_"/>
<copyField source="date" dest="_text_"/>
<copyField source="keywords" dest="_text_"/>
<copyField source="subject" dest="_text_"/>
<copyField source="description" dest="_text_"/>
<copyField source="author" dest="_text_"/>
<copyField source="title" dest="_text_"/>
<copyField source="content" dest="_text_"/>
声明字段类型
然后我们指定对于各种类型的字段,应当如何分析,包括分词和过滤。
<!-- 字段类型定义。"name"属性只用作标签。"class"属性和其它属性决定字段类型的行为
由"solr"开始的类名在org.apache.solr.analysis包中
-->
<!-- sortMissingLast 和 sortMissingFirst 属性目前只被内部排序为字符串或数值的类型支持。
包括"string", "boolean", "pint", "pfloat", "plong", "pdate", "pdouble"。
- 若sortMissingLast="true",则缺失字段的文档排到后面,不管排序方向
- 若sortMissingFirst="true",则缺失字段的文档排到前面,不管排序方向
- 若sortMissingLast="false"且sortMissingFirst="false" (默认),
则顺序排序时缺失字段文档在前面而逆序排序时缺失字段文档在后面
-->
<!-- StrField不被分析,会完好地被索引或存储 -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" multiValued="true" docValues="true" />
<!-- 布尔类型: "true" 或 "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="booleans" class="solr.BoolField" sortMissingLast="true" multiValued="true"/>
<!--
用KD树索引值的数值字段
点字段不支持字段缓存FieldCache,所以必须docValues="true"时才能用于排序、分片、函数等等
-->
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<fieldType name="pfloat" class="solr.FloatPointField" docValues="true"/>
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<fieldType name="pdouble" class="solr.DoublePointField" docValues="true"/>
<fieldType name="pints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="pfloats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<!-- 日期字段格式如 1995-12-31T23:59:59Z, 是比日期时间规范表示更受限的形式
http://www.w3.org/TR/xmlschema-2/#dateTime
最后的 "Z" 表示 UTC 时间且为强制的。
容许可选可选的小数秒: 1995-12-31T23:59:59.999Z
所有其它部分为强制的。
表达式中容许基于"NOW"计算时间, 如
NOW/HOUR
... 表示舍入到当前小时
NOW-1DAY
... 表示1天前
NOW/DAY+6MONTHS+3DAYS
... 表示6个月又3日后
-->
<!-- 日期字段的KD-树版本 -->
<fieldType name="pdate" class="solr.DatePointField" docValues="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<!-- 二进制数值类型。用Base64编码的字符串发送和接收 -->
<fieldType name="binary" class="solr.BinaryField"/>
<!-- solr.TextField容许指定定制的分析器为一个分词器和一些过滤器。
索引和查询时可以使用不同分析器。
可选的positionIncrementGap把空白加到同一文档的多个字段间以避免假词组。
关于定制分析器链的更多信息参见
http://lucene.apache.org/solr/guide/understanding-analyzers-tokenizers-and-filters.html#understanding-analyzers-tokenizers-and-filters
-->
<!-- 可以通过analyzer元素的class属性指定一个有默认构造器的分析器类,如:
<fieldType name="text_greek" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.el.GreekAnalyzer"/>
</fieldType>
-->
<!-- 一个在空白处切开的文本字段,用于单词的精确匹配 -->
<dynamicField name="*_ws" type="text_ws" indexed="true" stored="true"/>
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<!-- 一般文本字段,对跨语言有合理和泛化的默认: 用 StandardTokenizer分词,
从大小写无关的表"stopwords.txt"(默认为空)去除停用词, 小写化。
只在查询时用同义词。
-->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!--
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- SortableTextField与TextField类似, 但它支持并默认用docValues来基于前1024(可配置)字符排序和分片。
这使它在许多情况比TextField更有用,但占用更多磁盘空间; 这就是它们都存在的原因
-->
<dynamicField name="*_t_sort" type="text_gen_sort" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_txt_sort" type="text_gen_sort" indexed="true" stored="true"/>
<fieldType name="text_gen_sort" class="solr.SortableTextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- 默认适合英文的文本字段: 用StandardTokenizer分词, 去除英文停用词 (lang/stopwords_en.txt),
小写化、保护protwords.txt中词, 最后用Porter的词干提取。查询时支持同义词 -->
<dynamicField name="*_txt_en" type="text_en" indexed="true" stored="true"/>
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<!-- 大小写无关的停用词去除
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- 可选地可用较不积极的词干提取而不是 PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 默认适合英文的文本字段,加上积极的分词和自动词组特性。
与text_en类似,除了加入WordDelimiterGraphFilter以
启用在大小写变化时、字母数值边界、非字母数值边界分词和匹配。
这意味着"wi fi"匹配"WiFi"或"wi-fi".
-->
<dynamicField name="*_txt_en_split" type="text_en_splitting" indexed="true" stored="true"/>
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!-- 本例中我们只在查询时用同义词
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- 大小写无关的停用词去除
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 较不灵活的匹配,但更少伪匹配。可能不适合产品名,但可能适合SKUs。可在错误位置插入横线而仍然匹配 -->
<dynamicField name="*_txt_en_split_tight" type="text_en_splitting_tight" indexed="true" stored="true"/>
<fieldType name="text_en_splitting_tight" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- 这过滤器能去除在同一位置的重复词 - 有时在连用WordDelimiterGraphFilter和词干提取所造成 -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- 这过滤器能去除在同一位置的重复词 - 有时在连用WordDelimiterGraphFilter和词干提取所造成 -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<!-- 与text_general类似但它反转每个单词的字符以便让前方通配更高效。
-->
<dynamicField name="*_txt_rev" type="text_general_rev" indexed="true" stored="true"/>
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<dynamicField name="*_phon_en" type="phonetic_en" indexed="true" stored="true"/>
<fieldType name="phonetic_en" stored="false" indexed="true" class="solr.TextField" >
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.DoubleMetaphoneFilterFactory" inject="false"/>
</analyzer>
</fieldType>
<!-- 把整个字段值小写化并保持为完整单元 -->
<dynamicField name="*_s_lower" type="lowercase" indexed="true" stored="true"/>
<fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!--
在索引时用PathHierarchyTokenizerFactory的例子,从而路径查询匹配一路径或其后代
-->
<dynamicField name="*_descendent_path" type="descendent_path" indexed="true" stored="true"/>
<fieldType name="descendent_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
</fieldType>
<!--
在查询时用PathHierarchyTokenizerFactory的例子,从而路径查询匹配一路径或其祖先
-->
<dynamicField name="*_ancestor_path" type="ancestor_path" indexed="true" stored="true"/>
<fieldType name="ancestor_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/" />
</analyzer>
</fieldType>
<!-- 这类型把坐标索引为不同子字段。若定义了subFieldType,它指向一个类型和
一个动态字段定义,匹配 *___<类型名>. 或者若定义了subFieldSuffix
例如: 如果 subFieldType="double", 则坐标会索引到字段 myloc_0___double,myloc_1___double.
例如: 如果 subFieldSuffix="_d",则坐标索引到字段myloc_0_d,myloc_1_d
子字段是字段类型的实现细节,最终用户不用了解它
-->
<dynamicField name="*_point" type="point" indexed="true" stored="true"/>
<fieldType name="point" class="solr.PointType" dimension="2" subFieldSuffix="_d"/>
<!-- 用于地理搜索过滤和距离排序 -->
<fieldType name="location" class="solr.LatLonPointSpatialField" docValues="true"/>
<!-- 支持多值和多边形的地理字段类型,更多信息参见
http://lucene.apache.org/solr/guide/spatial-search.html
-->
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025" maxDistErr="0.001" distanceUnits="kilometers" />
<!-- 负载字段类型 -->
<fieldType name="delimited_payloads_float" stored="false" indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="float"/>
</analyzer>
</fieldType>
<fieldType name="delimited_payloads_int" stored="false" indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="integer"/>
</analyzer>
</fieldType>
<fieldType name="delimited_payloads_string" stored="false" indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="identity"/>
</analyzer>
</fieldType>
<!-- 一个语言的例子 (一般按ISO代码顺序) -->
<!-- 阿拉伯文 -->
<dynamicField name="*_txt_ar" type="text_ar" indexed="true" stored="true"/>
<fieldType name="text_ar" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- for any non-arabic -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ar.txt" />
<!-- normalizes ﻯ to ﻱ, etc -->
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.ArabicStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 保加利亚文 -->
<dynamicField name="*_txt_bg" type="text_bg" indexed="true" stored="true"/>
<fieldType name="text_bg" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_bg.txt" />
<filter class="solr.BulgarianStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 加泰罗尼亚文 -->
<dynamicField name="*_txt_ca" type="text_ca" indexed="true" stored="true"/>
<fieldType name="text_ca" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_ca.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ca.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Catalan"/>
</analyzer>
</fieldType>
<!-- 中日韩2-gram (日文形态学分析配置见text_ja -->
<dynamicField name="*_txt_cjk" type="text_cjk" indexed="true" stored="true"/>
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- normalize width before bigram, as e.g. half-width dakuten combine -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- for any non-CJK -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.CJKBigramFilterFactory"/>
</analyzer>
</fieldType>
<!-- 捷克文 -->
<dynamicField name="*_txt_cz" type="text_cz" indexed="true" stored="true"/>
<fieldType name="text_cz" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_cz.txt" />
<filter class="solr.CzechStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 丹麦文 -->
<dynamicField name="*_txt_da" type="text_da" indexed="true" stored="true"/>
<fieldType name="text_da" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_da.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Danish"/>
</analyzer>
</fieldType>
<!-- 德文 -->
<dynamicField name="*_txt_de" type="text_de" indexed="true" stored="true"/>
<fieldType name="text_de" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_de.txt" format="snowball" />
<filter class="solr.GermanNormalizationFilterFactory"/>
<filter class="solr.GermanLightStemFilterFactory"/>
<!-- 更不积极: <filter class="solr.GermanMinimalStemFilterFactory"/> -->
<!-- 更积极: <filter class="solr.SnowballPorterFilterFactory" language="German2"/> -->
</analyzer>
</fieldType>
<!-- 希腊文 -->
<dynamicField name="*_txt_el" type="text_el" indexed="true" stored="true"/>
<fieldType name="text_el" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- 希腊文对sigma的专门小写化 -->
<filter class="solr.GreekLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="false" words="lang/stopwords_el.txt" />
<filter class="solr.GreekStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 西班牙文 -->
<dynamicField name="*_txt_es" type="text_es" indexed="true" stored="true"/>
<fieldType name="text_es" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_es.txt" format="snowball" />
<filter class="solr.SpanishLightStemFilterFactory"/>
<!-- 更积极: <filter class="solr.SnowballPorterFilterFactory" language="Spanish"/> -->
</analyzer>
</fieldType>
<!-- 巴斯克文 -->
<dynamicField name="*_txt_eu" type="text_eu" indexed="true" stored="true"/>
<fieldType name="text_eu" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_eu.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Basque"/>
</analyzer>
</fieldType>
<!-- 波斯文 -->
<dynamicField name="*_txt_fa" type="text_fa" indexed="true" stored="true"/>
<fieldType name="text_fa" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<!-- 对于 ZWNJ -->
<charFilter class="solr.PersianCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.PersianNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fa.txt" />
</analyzer>
</fieldType>
<!-- 芬兰文 -->
<dynamicField name="*_txt_fi" type="text_fi" indexed="true" stored="true"/>
<fieldType name="text_fi" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fi.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Finnish"/>
<!-- 更不积极: <filter class="solr.FinnishLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 法文 -->
<dynamicField name="*_txt_fr" type="text_fr" indexed="true" stored="true"/>
<fieldType name="text_fr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- 去除 l'之类 -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_fr.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fr.txt" format="snowball" />
<filter class="solr.FrenchLightStemFilterFactory"/>
<!-- 更不积极: <filter class="solr.FrenchMinimalStemFilterFactory"/> -->
<!-- 更积极: <filter class="solr.SnowballPorterFilterFactory" language="French"/> -->
</analyzer>
</fieldType>
<!-- 爱尔兰文 -->
<dynamicField name="*_txt_ga" type="text_ga" indexed="true" stored="true"/>
<fieldType name="text_ga" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- 去除 d' 之类 -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_ga.txt"/>
<!-- 去除 n- 之类. 故意不偏移位置! -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/hyphenations_ga.txt"/>
<filter class="solr.IrishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ga.txt"/>
<filter class="solr.SnowballPorterFilterFactory" language="Irish"/>
</analyzer>
</fieldType>
<!-- 加利西亚文 -->
<dynamicField name="*_txt_gl" type="text_gl" indexed="true" stored="true"/>
<fieldType name="text_gl" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_gl.txt" />
<filter class="solr.GalicianStemFilterFactory"/>
<!-- 更不积极: <filter class="solr.GalicianMinimalStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 印地文 -->
<dynamicField name="*_txt_hi" type="text_hi" indexed="true" stored="true"/>
<fieldType name="text_hi" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<!-- 正规化 unicode 表示 -->
<filter class="solr.IndicNormalizationFilterFactory"/>
<!-- 正规化拼写变种 -->
<filter class="solr.HindiNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_hi.txt" />
<filter class="solr.HindiStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 匈牙利文 -->
<dynamicField name="*_txt_hu" type="text_hu" indexed="true" stored="true"/>
<fieldType name="text_hu" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_hu.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Hungarian"/>
<!-- 更不积极: <filter class="solr.HungarianLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 亚美尼亚文 -->
<dynamicField name="*_txt_hy" type="text_hy" indexed="true" stored="true"/>
<fieldType name="text_hy" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_hy.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Armenian"/>
</analyzer>
</fieldType>
<!-- 印尼文 -->
<dynamicField name="*_txt_id" type="text_id" indexed="true" stored="true"/>
<fieldType name="text_id" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_id.txt" />
<!-- 对于更不积极的方法 (只影响后缀), 把 stemDerivational 设为 false -->
<filter class="solr.IndonesianStemFilterFactory" stemDerivational="true"/>
</analyzer>
</fieldType>
<!-- 意大利文 -->
<dynamicField name="*_txt_it" type="text_it" indexed="true" stored="true"/>
<fieldType name="text_it" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- 去除 l' 之类 -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_it.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_it.txt" format="snowball" />
<filter class="solr.ItalianLightStemFilterFactory"/>
<!-- 更积极: <filter class="solr.SnowballPorterFilterFactory" language="Italian"/> -->
</analyzer>
</fieldType>
<!-- 基于形态学日文分析 (2-gram配置见text_cjk)
注记: 如果你想优化精度,在请求处理器用AND作为默认操作符 (q.op)
在优化召回率时则用默认的OR
-->
<dynamicField name="*_txt_ja" type="text_ja" indexed="true" stored="true"/>
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<!-- Kuromoji Japanese morphological analyzer/tokenizer (JapaneseTokenizer)
Kuromoji has a search mode (default) that does segmentation useful for search. A heuristic
is used to segment compounds into its parts and the compound itself is kept as synonym.
Valid values for attribute mode are:
normal: regular segmentation
search: segmentation useful for search with synonyms compounds (default)
extended: same as search mode, but unigrams unknown words (experimental)
For some applications it might be good to use search mode for indexing and normal mode for
queries to reduce recall and prevent parts of compounds from being matched and highlighted.
Use <analyzer type="index"> and <analyzer type="query"> for this and mode normal in query.
Kuromoji also has a convenient user dictionary feature that allows overriding the statistical
model with your own entries for segmentation, part-of-speech tags and readings without a need
to specify weights. Notice that user dictionaries have not been subject to extensive testing.
User dictionary attributes are:
userDictionary: user dictionary filename
userDictionaryEncoding: user dictionary encoding (default is UTF-8)
See lang/userdict_ja.txt for a sample user dictionary file.
Punctuation characters are discarded by default. Use discardPunctuation="false" to keep them.
-->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<!--<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>-->
<!-- Reduces inflected verbs and adjectives to their base/dictionary forms (辞書形) -->
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<!-- Removes tokens with certain part-of-speech tags -->
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt" />
<!-- Normalizes full-width romaji to half-width and half-width kana to full-width (Unicode NFKC subset) -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- Removes common tokens typically not useful for search, but have a negative effect on ranking -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt" />
<!-- Normalizes common katakana spelling variations by removing any last long sound character (U+30FC) -->
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<!-- Lower-cases romaji characters -->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- 拉脱维亚文 -->
<dynamicField name="*_txt_lv" type="text_lv" indexed="true" stored="true"/>
<fieldType name="text_lv" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_lv.txt" />
<filter class="solr.LatvianStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- 荷兰文 -->
<dynamicField name="*_txt_nl" type="text_nl" indexed="true" stored="true"/>
<fieldType name="text_nl" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_nl.txt" format="snowball" />
<filter class="solr.StemmerOverrideFilterFactory" dictionary="lang/stemdict_nl.txt" ignoreCase="false"/>
<filter class="solr.SnowballPorterFilterFactory" language="Dutch"/>
</analyzer>
</fieldType>
<!-- 挪威文 -->
<dynamicField name="*_txt_no" type="text_no" indexed="true" stored="true"/>
<fieldType name="text_no" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_no.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Norwegian"/>
<!-- 更不积极: <filter class="solr.NorwegianLightStemFilterFactory"/> -->
<!-- 单复数: <filter class="solr.NorwegianMinimalStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 葡萄牙文 -->
<dynamicField name="*_txt_pt" type="text_pt" indexed="true" stored="true"/>
<fieldType name="text_pt" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_pt.txt" format="snowball" />
<filter class="solr.PortugueseLightStemFilterFactory"/>
<!-- 更不积极: <filter class="solr.PortugueseMinimalStemFilterFactory"/> -->
<!-- 更积极: <filter class="solr.SnowballPorterFilterFactory" language="Portuguese"/> -->
<!-- 最积极: <filter class="solr.PortugueseStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 罗马文 -->
<dynamicField name="*_txt_ro" type="text_ro" indexed="true" stored="true"/>
<fieldType name="text_ro" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ro.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Romanian"/>
</analyzer>
</fieldType>
<!-- 俄文 -->
<dynamicField name="*_txt_ru" type="text_ru" indexed="true" stored="true"/>
<fieldType name="text_ru" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ru.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Russian"/>
<!-- 更不积极: <filter class="solr.RussianLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 瑞典文 -->
<dynamicField name="*_txt_sv" type="text_sv" indexed="true" stored="true"/>
<fieldType name="text_sv" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_sv.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Swedish"/>
<!-- 更不积极: <filter class="solr.SwedishLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- 泰文 -->
<dynamicField name="*_txt_th" type="text_th" indexed="true" stored="true"/>
<fieldType name="text_th" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ThaiTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_th.txt" />
</analyzer>
</fieldType>
<!-- 土耳其文 -->
<dynamicField name="*_txt_tr" type="text_tr" indexed="true" stored="true"/>
<fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.TurkishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="false" words="lang/stopwords_tr.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Turkish"/>
</analyzer>
</fieldType>
<!-- 相似性用于评价每个文档对查询的评分
这里可指定定制的Similarity或SimilarityFactory,但默认的对大多数应用良好
更多信息: http://lucene.apache.org/solr/guide/other-schema-elements.html#OtherSchemaElements-Similarity
-->
<!--
<similarity class="com.example.solr.CustomSimilarityFactory">
<str name="paramkey">param value</str>
</similarity>
-->
</schema>
以下列出一些在上面没有提及而仍然有用的字段类:
CollationField支持Unicode排序和范围查询CurrencyFieldType支持外币和汇率,常规配置形如<fieldType name="currency" class="solr.CurrencyFieldType" amountLongSuffix="_l_ns" codeStrSuffix="_s_ns" defaultCurrency="USD" currencyConfig="currency.xml" />,它指定了分别用于存储值和货币代码的字段后缀、默认货币和汇率(买入价与卖出价可以不同)来源,其中汇率文件形如:
<currencyConfig version="1.0">
<rates>
<rate from="USD" to="ARS" rate="4.333871" comment="ARGENTINA Peso" />
<rate from="USD" to="AUD" rate="1.025768" comment="AUSTRALIA Dollar" />
<rate from="USD" to="EUR" rate="0.743676" comment="European Euro" />
<rate from="USD" to="CAD" rate="1.030815" comment="CANADA Dollar" />
<rate from="EUR" to="USD" rate="0.5" />
</rates>
</currencyConfig>另外一种配置则通过API动态获取汇率,配置如<fieldType name="currency" class="solr.CurrencyFieldType" amountLongSuffix="_l_ns" codeStrSuffix="_s_ns" providerClass="solr.OpenExchangeRatesOrgProvider" refreshInterval="60" ratesFileLocation=
"http://www.openexchangerates.org/api/latest.json?app_id=你的程序密钥"/>
DateRangeField支持日期范围,容许Intersects(默认)、Contains和Within三类查询,指定查询方式的方法如fq={!field f=dateRange op=Contains}[2013 TO 2018],容许以下样子时间范围格式:2000-11表示2000年整个11月2000-11T13表示一个小时-0009表示10 BC这年,0 AD相当于1 BC[2000-11-01 TO 2014-12-01]表示一个日期范围[2014 TO 2014-12-01]表示2014年全年[* TO 2014-12-01]表示2014-12-01前
ExternalFileField从文件系统取得值,在个别字段(如点击计数)需要经常更新时有用。配置形如<fieldType name="entryRankFile" keyField="pkId" defVal="0" stored="false" indexed="false" class="solr.ExternalFileField"/>,字段应该保存到$SOLR_HOME/data目录中名为external_字段名或external_字段名.*,文件格式形如:
doc33=1.414
doc34=3.14159
doc40=42可以通过事件侦听器重新加载外部文件,如在solrsonfig.xml中加入:
<listener event="newSearcher" class="org.apache.solr.schema.ExternalFileFieldReloader"/>
<listener event="firstSearcher" class="org.apache.solr.schema.ExternalFileFieldReloader"/>EnumFieldType字段的值只能是预先定义的若干个值之一,配置如<fieldType name="priorityLevel" class="solr.EnumFieldType" docValues="true" enumsConfig="enumsConfig.xml" enumName="priority"/>,其中enumsConfig属性指定的文件形如:
<?xml version="1.0" ?>
<enumsConfig>
<enum name="priority">
<value>Not Available</value>
<value>Low</value>
<value>Medium</value>
<value>High</value>
<value>Urgent</value>
</enum>
</enumsConfig>ICUCollationField支持Unicode排序和范围查询,基于ICU4JPreAnalyzedField容许单词序列,可选地包括存储的值,默认JSON格式如:
{
"v":"1",
"str":"test ąćęłńóśźż",
"tokens": [
{"t":"one","s":123,"e":128,"i":22,"p":"DQ4KDQsODg8=","y":"word"},
{"t":"two","s":5,"e":8,"i":1,"y":"word"},
{"t":"three","s":20,"e":22,"i":1,"y":"foobar"}]}RandomSortField字段没有固定值,关于这种字段排序相当于随机排序UUIDField支持惟一标识符,传入NEW则Solr会新建一个
无模式模式
不指定模式时,Solr可以自动猜测字段的类型并加到模式中。对于默认的solrconfig.xml,应该有这段:
<updateProcessor class="solr.UUIDUpdateProcessorFactory" name="uuid"/>
<updateProcessor class="solr.RemoveBlankFieldUpdateProcessorFactory" name="remove-blank"/>
<updateProcessor class="solr.FieldNameMutatingUpdateProcessorFactory" name="field-name-mutating">
<str name="pattern">[^\w-\.]</str>
<str name="replacement">_</str>
</updateProcessor>
<updateProcessor class="solr.ParseBooleanFieldUpdateProcessorFactory" name="parse-boolean"/>
<updateProcessor class="solr.ParseLongFieldUpdateProcessorFactory" name="parse-long"/>
<updateProcessor class="solr.ParseDoubleFieldUpdateProcessorFactory" name="parse-double"/>
<updateProcessor class="solr.ParseDateFieldUpdateProcessorFactory" name="parse-date">
<arr name="format">
<str>yyyy-MM-dd'T'HH:mm:ss.SSSZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss,SSSZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss.SSS</str>
<str>yyyy-MM-dd'T'HH:mm:ss,SSS</str>
<str>yyyy-MM-dd'T'HH:mm:ssZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss</str>
<str>yyyy-MM-dd'T'HH:mmZ</str>
<str>yyyy-MM-dd'T'HH:mm</str>
<str>yyyy-MM-dd HH:mm:ss.SSSZ</str>
<str>yyyy-MM-dd HH:mm:ss,SSSZ</str>
<str>yyyy-MM-dd HH:mm:ss.SSS</str>
<str>yyyy-MM-dd HH:mm:ss,SSS</str>
<str>yyyy-MM-dd HH:mm:ssZ</str>
<str>yyyy-MM-dd HH:mm:ss</str>
<str>yyyy-MM-dd HH:mmZ</str>
<str>yyyy-MM-dd HH:mm</str>
<str>yyyy-MM-dd</str>
</arr>
</updateProcessor>
<updateProcessor class="solr.AddSchemaFieldsUpdateProcessorFactory" name="add-schema-fields">
<lst name="typeMapping">
<str name="valueClass">java.lang.String</str>
<str name="fieldType">text_general</str>
<lst name="copyField">
<str name="dest">*_str</str>
<int name="maxChars">256</int>
</lst>
<!-- 用作默认映射而非默认字段类型 -->
<bool name="default">true</bool>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">booleans</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.util.Date</str>
<str name="fieldType">pdates</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Long</str>
<str name="valueClass">java.lang.Integer</str>
<str name="fieldType">plongs</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Number</str>
<str name="fieldType">pdoubles</str>
</lst>
</updateProcessor>
<!-- update.autoCreateFields属性可设为false以禁用无模式模式 -->
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema" default="${update.autoCreateFields:true}"
processor="uuid,remove-blank,field-name-mutating,parse-boolean,parse-long,parse-double,parse-date,add-schema-fields">
<processor class="solr.LogUpdateProcessorFactory"/>
<processor class="solr.DistributedUpdateProcessorFactory"/>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain>
它表明除非属性update.autoCreateFields被设为false,否则在碰到模式没有定义的字段时会根据一定的规则企图解析字段的值,然后把字段加到模式中,并把它视为有对应的类型。值得注意的是,如果以后再企图索引文档遇到同一字段,如果值不符合这里猜测的类型,则会导致错误。
查看和修改模式
一种方法是在浏览器打开http://localhost:8983/solr/进入控制台后进入集合,然后在Schema选项卡中图形地查看并修改字段。
另一种方法是用基于HTTP的API,比如可以如下修改模式:
# 新增字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field":{
"name":"sell_by",
"type":"pdate",
"stored":true }
}' http://localhost:8983/solr/gettingstarted/schema
# 删除字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"delete-field" : { "name":"sell_by" }
}' http://localhost:8983/solr/gettingstarted/schema
# 重新定义字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"replace-field":{
"name":"sell_by",
"type":"date",
"stored":false }
}' http://localhost:8983/solr/gettingstarted/schema
# 新增动态字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-dynamic-field":{
"name":"*_s",
"type":"string",
"stored":true }
}' http://localhost:8983/solr/gettingstarted/schema
# 删除动态字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"delete-dynamic-field":{ "name":"*_s" }
}' http://localhost:8983/solr/gettingstarted/schema
# 重新定义动态字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"replace-dynamic-field":{
"name":"*_s",
"type":"text_general",
"stored":false }
}' http://localhost:8983/solr/gettingstarted/schema
# 新增字段类型
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field-type":{
"name":"myNewTextField",
"class":"solr.TextField",
"indexAnalyzer":{
"tokenizer":{
"class":"solr.PathHierarchyTokenizerFactory",
"delimiter":"/" }},
"queryAnalyzer":{
"tokenizer":{
"class":"solr.KeywordTokenizerFactory" }}}
}' http://localhost:8983/solr/gettingstarted/schema
# 删除字段类型
curl -X POST -H 'Content-type:application/json' --data-binary '{
"delete-field-type":{ "name":"myNewTxtField" }
}' http://localhost:8983/solr/gettingstarted/schema
# 重新定义字段类型
curl -X POST -H 'Content-type:application/json' --data-binary '{
"replace-field-type":{
"name":"myNewTxtField",
"class":"solr.TextField",
"positionIncrementGap":"100",
"analyzer":{
"tokenizer":{
"class":"solr.StandardTokenizerFactory" }}}
}' http://localhost:8983/solr/gettingstarted/schema
# 新建复制字段
V1 API
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-copy-field":{
"source":"shelf",
"dest":[ "location", "catchall" ]}
}' http://localhost:8983/solr/gettingstarted/schema
# 删除复制字段
curl -X POST -H 'Content-type:application/json' --data-binary '{
"delete-copy-field":{ "source":"shelf", "dest":"location" }
}' http://localhost:8983/solr/gettingstarted/schema
# 在同一请求中可以同时提供多个相同或不同的命令
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field":{
"name":"shelf",
"type":"myNewTxtField",
"stored":true },
"add-field":{
"name":"location",
"type":"myNewTxtField",
"stored":true },
"add-copy-field":{
"source":"shelf",
"dest":[ "location", "catchall" ]}
}' http://localhost:8983/solr/gettingstarted/schema
还可以如下查看模式:
# 获取完整模式
curl http://localhost:8983/solr/gettingstarted/schema
{
"responseHeader":{
"status":0,
"QTime":5},
"schema":{
"name":"example",
"version":1.5,
"uniqueKey":"id",
"fieldTypes":[{
"name":"alphaOnlySort",
"class":"solr.TextField",
"sortMissingLast":true,
"omitNorms":true,
"analyzer":{
"tokenizer":{
"class":"solr.KeywordTokenizerFactory"},
"filters":[{
"class":"solr.LowerCaseFilterFactory"},
{
"class":"solr.TrimFilterFactory"},
{
"class":"solr.PatternReplaceFilterFactory",
"replace":"all",
"replacement":"",
"pattern":"([^a-z])"}]}}],
"fields":[{
"name":"_version_",
"type":"long",
"indexed":true,
"stored":true},
{
"name":"author",
"type":"text_general",
"indexed":true,
"stored":true},
{
"name":"cat",
"type":"string",
"multiValued":true,
"indexed":true,
"stored":true}],
"copyFields":[{
"source":"author",
"dest":"text"},
{
"source":"cat",
"dest":"text"},
{
"source":"content",
"dest":"text"},
{
"source":"author",
"dest":"author_s"}]}}
# 获取字段,可用fl参数指定字段列表、
# 用includeDynamic参数true要求返回明确指定的动态字段、
# 用showDefaults参数true要求也返回隐式选项
curl http://localhost:8983/solr/gettingstarted/schema/fields
{
"fields": [
{
"indexed": true,
"name": "_version_",
"stored": true,
"type": "long"
},
{
"indexed": true,
"name": "author",
"stored": true,
"type": "text_general"
},
{
"indexed": true,
"multiValued": true,
"name": "cat",
"stored": true,
"type": "string"
},
"..."
],
"responseHeader": {
"QTime": 1,
"status": 0
}
}
# 获取动态字段,可用showDefaults参数true返回隐式参数
curl http://localhost:8983/solr/gettingstarted/schema/dynamicfields
{
"dynamicFields": [
{
"indexed": true,
"name": "*_coordinate",
"stored": false,
"type": "tdouble"
},
{
"multiValued": true,
"name": "ignored_*",
"type": "ignored"
},
{
"name": "random_*",
"type": "random"
},
{
"indexed": true,
"multiValued": true,
"name": "attr_*",
"stored": true,
"type": "text_general"
},
{
"indexed": true,
"multiValued": true,
"name": "*_txt",
"stored": true,
"type": "text_general"
}
"..."
],
"responseHeader": {
"QTime": 1,
"status": 0
}
}
# 获取字段类型,可用showDefaults参数true返回隐式参数
curl http://localhost:8983/solr/gettingstarted/schema/fieldtypes
{
"fieldTypes": [
{
"analyzer": {
"class": "solr.TokenizerChain",
"filters": [
{
"class": "solr.LowerCaseFilterFactory"
},
{
"class": "solr.TrimFilterFactory"
},
{
"class": "solr.PatternReplaceFilterFactory",
"pattern": "([^a-z])",
"replace": "all",
"replacement": ""
}
],
"tokenizer": {
"class": "solr.KeywordTokenizerFactory"
}
},
"class": "solr.TextField",
"dynamicFields": [],
"fields": [],
"name": "alphaOnlySort",
"omitNorms": true,
"sortMissingLast": true
},
{
"class": "solr.FloatPointField",
"dynamicFields": [
"*_fs",
"*_f"
],
"fields": [
"price",
"weight"
],
"name": "float",
"positionIncrementGap": "0",
}]
}
# 获取复制字段,可用参数source.fl和dest.fl限制返回的复制字段
curl http://localhost:8983/solr/gettingstarted/schema/copyfields
{
"copyFields": [
{
"dest": "text",
"source": "author"
},
{
"dest": "text",
"source": "cat"
},
{
"dest": "text",
"source": "content"
},
{
"dest": "text",
"source": "content_type"
},
],
"responseHeader": {
"QTime": 3,
"status": 0
}
}
# 获取模式名
curl http://localhost:8983/solr/gettingstarted/schema/name
{
"responseHeader":{
"status":0,
"QTime":1},
"name":"example"}
# 获取模式版本
curl http://localhost:8983/solr/gettingstarted/schema/version
{
"responseHeader":{
"status":0,
"QTime":2},
"version":1.5}
# 获取主键
curl http://localhost:8983/solr/gettingstarted/schema/uniquekey
{
"responseHeader":{
"status":0,
"QTime":2},
"uniqueKey":"id"}
# 获取全局相似度参数
curl http://localhost:8983/solr/gettingstarted/schema/similarity
{
"responseHeader":{
"status":0,
"QTime":1},
"similarity":{
"class":"org.apache.solr.search.similarities.DefaultSimilarityFactory"}}
# 上述各API都可用wt参数指定返回格式,默认json
用Solr索引数据
简单索引
用Solr索引数据的最简单方法是用bin/post命令,它的用法如下:
用法: post -c <集合> [选项] <文件|目录|URL|-d ["...",...]>
或 post -help
集合名默认为DEFAULT_SOLR_COLLECTION
选项
=======
Solr 选项:
-url <基Solr update URL> (覆盖集合、主机和端口)
-host <主机> (默认: localhost)
-p 或 -port <端口> (默认: 8983)
-commit yes|no (端口: yes)
-u 或 -user <用户:密码> (设置BasicAuth秘密)
网络爬虫选项:
-recursive <深度> (默认: 1)
-delay <秒> (默认: 10)
目录爬虫选项:
-delay <秒> (默认: 0)
stdin/args 选项:
-type <内容类型> (默认: application/xml)
其它选项:
-filetypes <类型>[,<类型>,...] (默认: xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log)
-params "<键>=<值>[&<键>=<值>...]" (值必须用URL编码; 它们通过Solr update请求传递)
-out yes|no (默认: no; yes会把Solr响应输出到终端)
-format solr (把application/json内容作为命令发送到/update而非/update/json/docs)
例子:
* JSON文件: bin/post -c wizbang events.json
* XML文件: bin/post -c records article*.xml
* CSV文件: bin/post -c signals LATEST-signals.csv
* 目录: bin/post -c myfiles ~/Documents
* 爬虫: bin/post -c gettingstarted http://lucene.apache.org/solr -recursive 1 -delay 1
* 标准输入 (stdin): echo '{commit: {}}' | bin/post -c my_collection -type application/json -out yes -d
* 文本数据: bin/post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'
索引结构化数据
要传入XML数据,可以这样子:
curl http://localhost:8983/solr/my_collection/update -H "Content-Type: text/xml" --data-binary '
<update><!-- 只有一个命令时不必套这一层update -->
<add><!-- 新增文档,commitWithin属性可指定多少毫秒内提交,overwrite属性(默认true)指定是否覆盖原有文档 -->
<doc><!-- 待索引的文档 -->
<field name="authors">Patrick Eagar</field><!-- 待索引的文档的各字段 -->
<field name="subject">Sports</field>
<field name="dd">796.35</field>
<field name="isbn">0002166313</field>
<field name="yearpub">1982</field>
<field name="publisher">Collins</field>
<!-- 也可以用doc标签嵌套文档 -->
</doc>
</add>
<delete><!-- 删除文档 -->
<id>0002166313</id><!-- 按主键删除文档 -->
<id>0031745983</id>
<query>subject:sport</query><!-- 删除所有匹配这查询的结果文档 -->
<query>publisher:penguin</query>
</delete>
<commit waitSearcher="false" expungeDeletes="true"/>
<!-- 提交,waitSearcher决定是否阻塞至变更可见(默认true)、expungeDeletes(默认false)决定是否合并超过10%文档被删除的段 -->
<optimize waitSearcher="false"/>
<!-- 优化内部数据结构,waitSearcher决定是否阻塞至变更可见(默认true)、maxSegments表示合并到不超过指定段数(默认1) -->
</update>'
# 如果你传入的数据不匹配上述模式,可以加上请求参数tr指定用于转换的XSLT文件,但XSLT文件应当位于配置集目录的conf/xslt子目录
类似地,要传入JSON数据可以为这样子:
curl -X POST -H 'Content-Type: application/json'
'http://localhost:8983/solr/my_collection/update' --data-binary '
{
"add": {
"doc": {
"id": "DOC1",
"my_field": 2.3,
"my_multivalued_field": [ "aaa", "bbb" ]}},
"add": {
"commitWithin": 5000,
"overwrite": false,
"doc": {
"f1": "v1",
"f1": "v2"}},
"commit": {},
"optimize": { "waitSearcher":false },
"delete": { "id":"ID" },
"delete": { "query":"QUERY" }}'
# 嵌套文档放到字段_childDocuments_中
# 在请求路径后加上/json的话可省略contentType=application/json头
# 在请求路径后加上/json/docs的话还可以直接放JSON格式的文档或它们的列表而不用加上命令部分
# 请求参数中可指定一些选项:
# split:把JSON分成子文档的路径列表(用|分隔),只有一个文档时为/
# f:用于指定字段对应的JSON路径,形如 target-field-name:json-path,可以使用通配符,默认是对应于完全限定名
# mapUniqueKeyOnly:把所有字段索引到默认字段,只把uniqueKey字段(没有则生成UUID)对应到模式中主键
# df:默认字段
# srcField:保存原始JSON的字段,只能用于split=/时
# echo:是否返回文档而非索引
要传入CSV数据可以为这样子
curl 'http://localhost:8983/solr/my_collection/update?commit=true' --data-binary
@example/exampledocs/books.csv -H 'Content-type:application/csv'
# 在请求路径后加上/csv的话可省略contentType=application/csv头
# 请求参数 选项 或 f.选项.字段 中可指定一些选项:
# separator:字段分隔符,默认","
# trim:移除两边空格,默认false
# header:首行是否标题,是的话将用作默认的字段名
# fieldnames:使用的字段列表,用逗号分隔
# literal:字段的一个字面值
# skip:忽略的字段列表,用逗号分隔
# skipLines:忽略前若干行,默认0
# encapsulator:用于引用字面值的引号
# escape:转义字符,与encapsulator不能同时生效
# keepEmpty:是否保留长度为零的字段,默认false
# map:形如 value:replacement 表示把一个值替换为另一个
# split:是否把字段的值分解为多个值
# overwrite:是否基于主键覆盖重复文档,默认true
# commit:增加后提交
# commitWithin:在指定毫秒内提交
# rowid:行号对应的字段
# rowidOffset:首行的行号,默认0
索引非结构化文档
Solr可以利用Tika库索引PDF、HTML、OpenDocument和Microsoft office格式的文档。在solrconfig中默认应该已经启用它:
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="lowernames">true</str>
<str name="fmap.meta">ignored_</str>
<str name="fmap.content">_text_</str>
</lst>
</requestHandler>
然而这配置把内容对应到_text_而这通常不是stored的,从而不能作为搜索结果返回和加亮,一个更适合全文搜索的配置可能形如:
<requestHandler name="/update/extract" class="org.apache.solr.handler.extraction.ExtractingRequestHandler">
<lst name="defaults">
<str name="lowernames">true</str>
<str name="fmap.content">content</str>
<str name="uprefix">ignored_</str>
<str name="captureAttr">true</str>
</lst>
</requestHandler>
以下是一些选项的用途:
capture表示是否把元素的内容同时索引到特定字段captureAttr把属性索引到另外的字段,按元素命名commitWithin表示在指定毫秒内提交date.formats日期格式defaultField指定在没有uprefix参数且不确定字段时用的默认字段extractOnly是否提取内容并返回而不索引,默认falseextractFormat提取内容的序列化格式,可以为默认的xml或text,只用于extractOnly时fmap.源字段指定把Tika提取到字段对应到哪个文档字段ignoreTikaException是否在出现异常时仍然索引部分元数据literal.字段指定字段的一个值literalsOverride指定覆盖字段的其它值,默认truelowernames用于指定是否把所有字段小写化multipartUploadLimitInKB用于指定最大容许的文档大小passwordsFile用于指定把文件名对应到密码的文件路径resource.name用于指定文件名,可能被用于检测文件格式resource.password用作解密PDF或OOXML文档的密码tika.config用于指定Tika配置文件uprefix用于指定给所有在模式中没有定义的Tika字段加上指定前缀作为文档字段xpath用于指定只返回匹配这XPath表达式的内容
然后就可以用HTTP API索引如:
curl 'http://localhost:8983/solr/集合/update/extract?commit=true' -F "给Solr看的文件名=@文件位置"
当然,我们也可以用SolrJ提供的Java API:
public static void main (String[] args)throws IOException,SolrServerException{
SolrClient client=new HttpSolrClient.Builder("http://localhost:8983/solr/my_collection").build();
ContentStreamUpdateRequest req=new ContentStreamUpdateRequest("/update/extract");
req.addFile(new File("文件名"));
req.setParam(ExtractingParams.EXTRACT_ONLY,"true");
NamedList<Object> result=client.request(req);
System.out.println("Result: "+result);
}
从数据仓库导入数据
要启用这功能,在solrconfig.xml中加入:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">数据仓库配置文件路径</str>
</lst>
</requestHandler>
其中数据仓库配置文件形如:
<dataConfig>
<dataSource driver="org.hsqldb.jdbcDriver"
url="${dataimporter.request.jdbcurl}"
user="${dataimporter.request.jdbcuser}"
password="${dataimporter.request.jdbcpassword}" />
<document>
<entity name="item" query="select * from item" deltaQuery=
"select id from item where last_modified >'${dataimporter.last_index_time}'">
<field column="NAME" name="name" />
<entity name="feature"
query="select DESCRIPTION from FEATURE where ITEM_ID='${item.ID}'"
deltaQuery="select ITEM_ID from FEATURE where last_modified > '${dataimporter.last_index_time}'"
parentDeltaQuery="select ID from item where ID=${feature.ITEM_ID}"> 5
<field name="features" column="DESCRIPTION" />
</entity>
<entity name="item_category"
query="select CATEGORY_ID from item_category where ITEM_ID='${item.ID}'"
deltaQuery="select ITEM_ID, CATEGORY_ID from item_category where last_modified > '${dataimporter.last_index_time}'"
parentDeltaQuery="select ID from item where ID=${item_category.ITEM_ID}">
<entity name="category"
query="select DESCRIPTION from category where ID = '${item_category.CATEGORY_ID}'"
deltaQuery="select ID from category where last_modified >'${dataimporter.last_index_time}'"
parentDeltaQuery="select ITEM_ID, CATEGORY_ID from item_category where CATEGORY_ID=${category.ID}">
<field column="description" name="cat" />
</entity>
</entity>
</entity>
</document>
</dataConfig>
- 数据源用于表示数据来源
ContentStreamDataSource用POST数据FieldReaderDataSource用数据库中某字段保存的XMLFileDataSource用文件系统中文件,可用参数basePath和encoding(默认UTF-8)JdbcDataSource用数据库(默认),可用参数driver、url、user、password和encryptKeyFile指定数据库,并可用batchSize(默认500,-1表示不预取)URLDataSource用URL定位数据可用参数baseURL、connectionTimeout(默认5000毫秒)、encoding、readTimeout(默认10000毫秒)
- 处理器用于提取数据,可用的公共参数有:
dataSource(数据源)、name(名称,必须)、pk(主键,用于增量导入)、processor(默认SqlEntityProcessor)、onError(abort、skip或continue)、preImportDeleteQuery(默认*:*)、postImportDeleteQuery、rootEntity、transformer、cacheImpl、cacheKey、cacheLookup、where、child="true"、join="zipper"SqlEntityProcessor用于从数据库中获取数据,参数有query(用于获取行的SQL查询,必须)、deltaQuery、parentDeltaQuery、deletedPkQuery、deltaImportQuery(没有则通过修改query得),其中可用名字空间${dataimporter.delta.<column-name>}XPathEntityProcessor用于索引XML数据,选项有url(必须)、stream、forEach(XPath表达式)、xsl、useSolrAddSchema(是否格式如update请求体),每个字段又可以有选项xpath(必须,XPath表达式)、commonField(是否在出现后复制到后来的记录)、flatten(默认false)MailEntityProcessor用于通过IMAP协议获取邮件,参数有user(必须)、password(必须)、host(必须)、protocol(必须imap、imaps、gimap或gimaps)、fetchMailsSince(形如yyyy-MM-dd HH:mm:ss)、folders(用,分隔)、recurse(默认true)、include(信箱名的正则表达式列表,用逗号分隔)、exclude(信箱名的正则表达式列表,用逗号分隔)、processAttachement、processAttachments(默认true)、includeContent(默认true)TikaEntityProcessor用Tika提取文档,选项有url(必须)、htmlMapper(default或identity)、format(text、xml、html或none,默认text)、parser(默认org.apache.tika.parser.AutoDetectParser)、fields、extractEmbedded、onErrorFileListEntityProcessor用于生成一些文件,生成的字段有fileAbsolutePath、fileDir、fileSize、fileLastModified和file,选项有fileName(必须)、basedir(必须)、recursive(默认false)、excludes(正则表达式)、newerThan(形如yyyy-MM-ddHH:mm:ss或日期表达式)、olderThan(同前)、rootEntity(应设为false)LineEntityProcessor对过滤后每行返回一个rawLine字段,选项有url(必须)、acceptLineRegex、omitLineRegexPlainTextEntityProcessor把完整的内容读到plainText字段,选项有url(必须)SolrEntityProcessor从其它Solr实例和核读取数据,选项有url(必须)、query(必须)、fq、rows(默认50)、fl、qt、wt(javabin或xml)、timeout(默认300秒)、cursorMark="true"、sort="id asc"
- 转换器用于处理字段值,可在
entity标签中属性transformer用,分隔列表的形式指定需要用到的转换器。ClobTransformer用于基于数据库中的CLOB构造字符串,只用在对应field标签中加上属性clob="true",有需要时也可指定sourceColNameDateFormatTransformer用于转换日期格式,只用在有关的field标签指定属性dateTimeFormat(原来格式),有需要时也可指定sourceColName、locale(BCP 47语言标签)HTMLStripTransformer用于去除HTML标签,只用在对应field标签中加上属性stripHTML="true"LogTransformer用于把数据记录到日志,需要时也可在entity标签加入属性logTemplate和logLevelNumberFormatTransformer用于修改数值格式,只用在对应field标签中加上属性formatStyle(number、percent、integer或currency),有需要时也可指定sourceColName、locale(BCP 47语言标签)RegexTransformer用于作文本处理如替换或切割,只用在对应field标签中加上属性regex(用于匹配的正则表达式),有需要时也可指定sourceColName、splitBy、groupNames(分割后各部分对应字段,用,分隔)、replaceWithScriptTransformer容许用脚本语言如Javascript、JRuby、Jython、Groovy和BeanShell转换,函数应当以行(类型为Map<String,Object>)为参数,可以修改字段。脚本应当写在数据仓库配置文件顶级的script元素内,而转换器属性值为script:函数名。TemplateTransformer容许生成或修改字段的值,只用在字段的template属性设为模板,其中可用${实体.字段}来引用。
完成配置后可以用HTTP API开始导入数据:
| 命令 | 用途 | URL |
|---|---|---|
| abort | 中止正在进行的操作 | http://localhost:8983/solr/dih/dataimport?command=abort |
| delta-import | 增量导入,支持选项clean、commit、optimize和debug |
http://localhost:8983/solr/dih/dataimport?command=delta-import |
| full-import | 开始完整导入,支持选项clean(默认true)、commit(默认true)、optimize(默认true)、debug(默认false)、entity(默认为所有实体,可指定多次)、synchronous(默认false) |
http://localhost:8983/solr/dih/dataimport?command=full-import |
| reload-config | 重新加载配置文件 | http://localhost:8983/solr/dih/dataimport?command=reload-config |
| status | 返回已增加文档数、已删除文档数、已执行查询、已获取行数、状态等等 | http://localhost:8983/solr/dih/dataimport?command=status |
| show-config | 返回配置 | http://localhost:8983/solr/dih/dataimport?command=show-config |
去重复
有时候,索引时会碰到近乎重复的文档,重复索引这些文档不仅浪费空间,而且会干扰排序用的评分。去重复一般是通过在文档中加入一个字段记录文档的签名完成的,在索引时对待索引文档计算签名,如果发现它与索引中某个签名匹配便可有把握地认为文档已经被索引过。在solrconfig.xml中可以加入这段来启用去重复功能:
<updateRequestProcessorChain name="dedupe">
<processor class="solr.processor.SignatureUpdateProcessorFactory">
<bool name="enabled">true</bool>
<str name="signatureField">id</str>
<bool name="overwriteDupes">false</bool>
<str name="fields">name,features,cat</str>
<str name="signatureClass">solr.processor.Lookup3Signature</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
<requestHandler name="/update" class="solr.UpdateRequestHandler" >
<lst name="defaults">
<str name="update.chain">dedupe</str>
</lst>
</requestHandler>
其中,
signatureClass指定用于生成签名的办法:org.apache.solr.update.processor.Lookup3Signature(默认)使用64位散列值作去除严格重复org.apache.solr.update.processor.MD5Signature使用128位散列值作去除严格重复,比上者慢org.apache.solr.update.process.TextProfileSignature用于去除近似重复,适合长文本
fields为用于生成签名的字段列表,默认为所有字段signatureField为用于保存签名的字段名,默认为signatureField,必须确保模式中已经定义这字段可索引如<field name="signatureField" type="string" stored="true" indexed="true" multiValued="false" />enabled表示是否启用去重复,默认trueoverwriteDupes表示在发现重复时用待索引文档代替已索引的重复文档,默认true
语言识别
在索引文档时我们可能希望检测字段的语言并把语言作为文档的一个字段,以下是一个典型配置:
<updateRequestProcessorChain name="langid">
<!-- 另一个检测器是org.apache.solr.update.processor.LangDetectLanguageIdentifierUpdateProcessorFactory -->
<processor class="org.apache.solr.update.processor.TikaLanguageIdentifierUpdateProcessorFactory">
<!-- 待检测语言的字段 -->
<str name="langid.fl">text,title,subject,description</str>
<!-- 检测到的语言加到哪个字段 -->
<str name="langid.langField">language_s</str>
<!-- 检测不到时视为什么语言 -->
<str name="langid.fallback">en</str>
<!-- 更多参数参见文档 -->
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
用Solr搜索
查询API
Solr提供了RESTful的API,可以用HTTP的GET方法进行查询,查询和其它参数用GET参数给出即可,例如:
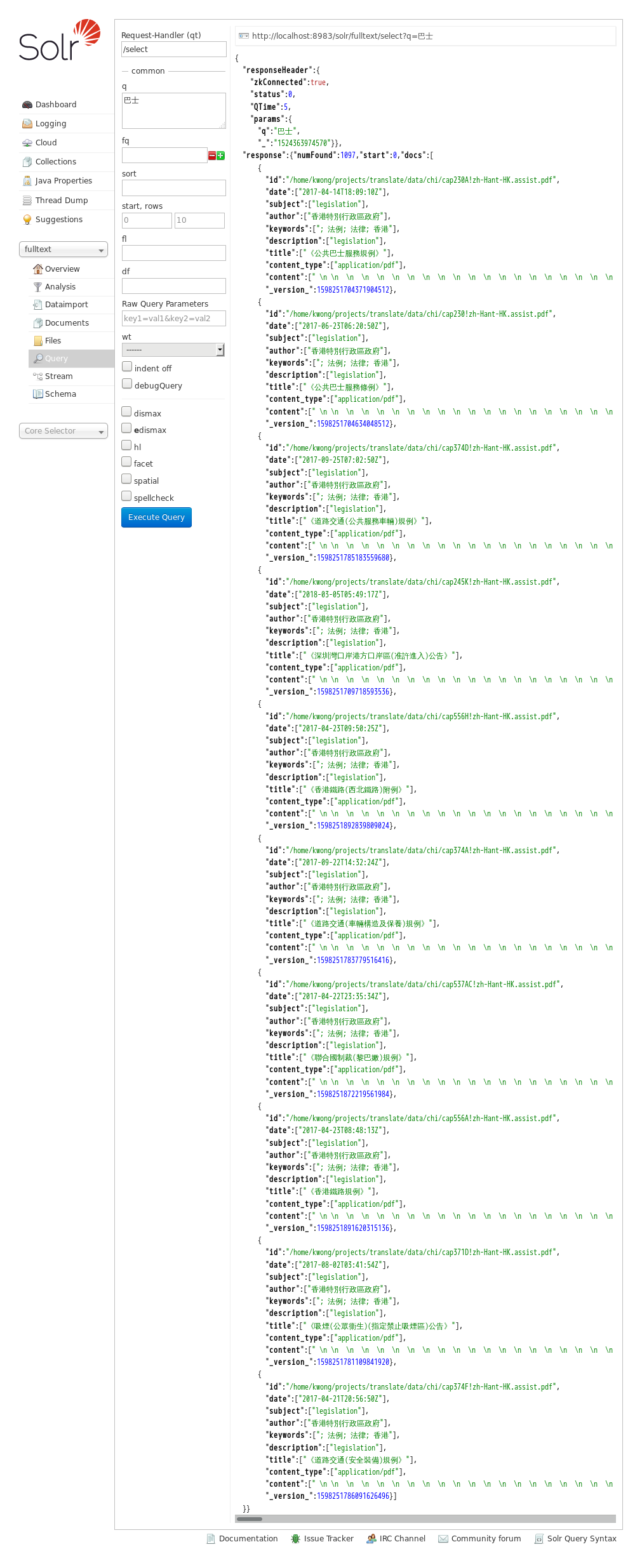
curl "http://localhost:8983/solr/集合/query?q=一些东西&fq=inTitle:gov"
另一种方式则是把JSON格式的查询以HTTP的POST方法提供,例如:
curl http://localhost:8983/solr/techproducts/query -d '
{
"query" : "一些东西",
"filter" : "inTitle:gov"
}'
值得指出的是:
- 多次指定单值参数,最后指定的值生效
- 多次指定多值参数,它们会连接起来
- 形如
json.<path>的请求参数的值会插入到JSON体中合适地方(晚于JSON体被解析) - 在JSON体中用
query、filter、offset、limit而非q、fq、start、rows
返回的结果通常是JSON格式的,形如:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":5,
"params":{
"q":"\"基本法\"",
"fl":"id,date,title,score",
"_":"1524202118322"}},
"response":{"numFound":211,"start":0,"maxScore":1.9131931,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A203!zh-Hant-HK.assist.pdf",
"date":["2017-02-15T04:09:04Z"],
"title":["全國人民代表大會關於批准香港特別行政區基本法起草委員會關於設立全國人民代表大會常務委員會香港特別行政區基本法委員會的建議的決定(1990年4月4日第七屆全國人民代表大會第三次會議通過)"],
"score":1.9131931},
{
"id":"/home/kwong/projects/translate/data/chi/A114!zh-Hant-HK.assist.pdf",
"date":["2017-02-15T04:34:18Z"],
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》第十三條第一款和第十九條的解釋(2011年8月26日第十一屆全國人民代表大會常務委員會第二十二次會議通過)"],
"score":1.9117998},
{
"id":"/home/kwong/projects/translate/data/chi/A106!zh-Hant-HK.assist.pdf",
"date":["2017-02-15T03:16:14Z"],
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》第二十二條第四款和第二十四條第二款第(三)項的解釋 (1999年6月26日第九屆全國人民代表大會常務委員會第十次會議通過)"],
"score":1.9054346},
{
"id":"/home/kwong/projects/translate/data/chi/A206!zh-Hant-HK.assist.pdf",
"date":["2017-06-02T07:57:24Z"],
"title":["全國人民代表大會常務委員會關於根據《中華人民共和國香港特別行政區基本法》第一百六十條處理香港原有法律的決定(1997年2月23日第八屆全國人民代表大會常務委員會第二十四次會議通過)"],
"score":1.9049824},
{
"id":"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf",
"date":["2018-01-05T04:06:43Z"],
"title":["中華人民共和國香港特別行政區基本法(1990年4月4日第七屆全國人民代表大會第三次會議通過)"],
"score":1.904556},
{
"id":"/home/kwong/projects/translate/data/chi/A115!zh-Hant-HK.assist.pdf",
"date":["2017-01-19T10:46:04Z"],
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》第一百零四條的解釋"],
"score":1.9008186},
{
"id":"/home/kwong/projects/translate/data/chi/A108!zh-Hant-HK.assist.pdf",
"date":["2017-02-15T04:15:28Z"],
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》第五十三條第二款的解釋(2005年4月27日第十屆全國人民代表大會常務委員會第十五次會議通過)"],
"score":1.8961817},
{
"id":"/home/kwong/projects/translate/data/chi/A212!zh-Hant-HK.assist.pdf",
"date":["2017-09-06T09:00:47Z"],
"title":["全國人民代表大會常務委員會關於香港特別行政區行政長官普選問題和 2016 年立法會產生辦法的決定(2014年8月31日第十二屆全國人民代表大會常務委員會第十次會議通過)"],
"score":1.8927253},
{
"id":"/home/kwong/projects/translate/data/chi/A107!zh-Hant-HK.assist.pdf",
"date":["2017-02-13T08:21:10Z"],
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》附件一第七條和附件二第三條的解釋(2004年4月6日第十屆全國人民代表大會常務委員會第八次會議通過)"],
"score":1.8785428},
{
"id":"/home/kwong/projects/translate/data/chi/A104!zh-Hant-HK.assist.pdf",
"date":["2017-07-05T06:16:00Z"],
"title":["全國人民代表大會關於《中華人民共和國香港特別行政區基本法》的決定 (1990年4月4日第七屆全國人民代表大會第三次會議通過)"],
"score":1.8726296}]
}}
| 参数 | 用途 | 默认值 |
|---|---|---|
defType |
查询解析器,下一小节会进一步介绍 | lucene |
sort |
排序条件列表(用,分隔,由重要到不重要),每个条件由量(可以是score、docValues="true"的基本字段、单值文本字段、或函数结果)、空格和顺序(asc或desc) |
|
start |
返回的首个结果的序号 | 0 |
rows |
返回的结果个数 | 10 |
fq |
附加查询,返回的结果必须满足这查询(但不影响评分),往往比直接写到主查询时更快 | |
fl |
返回结果中包含的字段列表(用,分隔,每个字段前可以加别名:来引入别名),其中字段必须为stored="true"或docValues="true"的,另外可用score、函数结果或转换器 |
|
debug |
返回的调试信息类型(可指定多次):query、timing、results、all(或true) |
|
explainOther |
比较查询,会返回它与主查询分别前列结果评分差异的说明 | |
timeAllowed |
限时(毫秒),超时的话结果计数和分片计数等统计数据可能不准确 | |
segmentTerminateEarly |
是否容许提早退出,提早退出的话结果计数和分片计数等统计数据可能不准确 | false |
omitHeader |
是否去除返回头字段responseHeader |
false |
wt |
返回格式化器,可能值取决于solrconfig.xml中的queryResponseWriter标签 |
json |
cache |
是否缓存所有查询(包括过滤查询)结果 | true |
logParamsList |
记录到日志的参数列表(用,分隔) |
全部 |
echoParams |
在返回中显示哪些请求参数,可以是none、explicit(回显所有显式参数和64位时间戳_)、all(再显示来自solrconfig.xml的隐式参数) |
explicit |
至于上面提到的函数结果可以有以下形式:
- 数值或字符串字面值
- 字段
- 参数引用
${参数} - 函数应用
abs(x)表示x的绝对值childfield(字段,...)对{!parent}查询表示子文档特定字段的值concat(字符串,...)表示把字符串连接起来def(字段,默认值)表示特定字段的值(没有则默认值)div(x,y)表示商dist(1,x1,...,xn,y1,...,yn)表示两个向量的马氏距离dist(2,x1,...,xn,y1,...,yn)表示两个向量的欧氏距离docfreq(field,val)表示特定字段有特定值的文档数field(字段)表示特定数值docValues或indexed字段的值field(字段,min)表示特定数值docValues字段的最小值field(字段,max)表示特定数值docValues字段的最大值geodist(sfield,latitude,longitude)表示距离hsin(2,布尔值,x1,...,xn,y1,...,yn)表示球面上两点(用弧度表示)的球面距离,结果是否弧度取决于布尔值idf(字段,项)表示全局倒数文档频率if(布尔值,值1,值2)在布尔值为真时表示值1否则值2linear(x,m,c)表示mx+c的值log(x)表示x的常用对数map(x,min,max,target)当x介于min与max之间时表示target否则表示xmap(x,min,max,target,default)当x介于min与max之间时表示target否则表示defaultmax(x,y,...)表示最大值maxdoc()表示索引中总文档数min(x,y,...)表示最小值ms()相当于ms(NOW)ms(时间)表示从UTC时间1970年1月1日到指定时间经过的毫秒数ms(时间1,时间2)表示从时间2到时间1的毫秒数norm(字段)表示字段的索引时提升因子与根据相似性的长度归一化因子的积numdocs()表示索引中没有被标记为已删除的文档数ord(字段)表示文档按特定字段的排序,从1开始,没有该字段则为0payload(字段,项)和下面同,只是默认值为0.0payload(字段,项,默认值)和下面同,只是函数为average,默认值可以为常数、字段或浮点数函数结果payload(字段,项,默认值,函数)表示项的有效负载的总结,没有则表示默认值,其中函数可以为min、max、average或firstpow(x,y)表示幂product(x,y,...)或mul(x,y,...)表示积query(子查询,默认值)表示文档对子查询的评分,不匹配则取默认值recip(x,m,a,b)表示a/(mx+b)的值rord(字段)表示文档按特定字段的反向序号scale(x, minTarget, maxTarget)在x大于maxTarget时表示maxTarget,在x小于minTarget时表示minTarget,否则表示xsqedist(x1,...,xn,y1,...,yn)表示两个向量的欧氏距离的平方,通常用于节省开方所需的时间sqrt(x)表示x的平方根strdist(字符串,字符串,算法)表示两个字符串间距离,其中算法可以为jw(Jaro-Winkler)、edit(编辑距离)、ngram(N-gram距离,可再加参数n,否则默认2-gram)或完全限定类名(有无参构造器)sub(x,y)表示两个数的差sum(x,y,...)表示一些数之和sumtotaltermfreq(字段)或sttf(字段)表示索引中特定字段的总项数termfreq(字段,项)表示文档中项的出现次数tf(字段,项)表示项频因子top(函数结果)表示在整个索引中求值其参数totaltermfreq(字段,项)或ttf(字段,项)表示整个索引中项出现的次数and(布尔值,...)表示与or(布尔值,布尔值)表示或xor(布尔值,布尔值)表示异或not(布尔值)表示否定exists(字段)表示字段的存在性gt(x,y)表示大于gte(x,y)表示大于或等于lt(x,y)表示小于lte(x,y)表示小于或等于eq(x,y)表示等于
至于上面提到的转换器可以有以下形式(另外在solrconfig.xml中可以用transformer标签配置转换器):
[value v=值 t=类型]表示给定值,类型默认为字符串[explain style=格式]表示调试信息,其中格式可以为text、html或nl[child parentFilter=祖先过滤查询 childFilter=后代过滤查询 limit=最多返回的后代数]表示后代文档列表,其中不指定childFilter则表示所有后代,不指定limit表示10[shard]表示文档来自的结点[docid]表示文档的Lucene内部ID[elevated]表示文档是否被elevator组件置顶(在elevateIds参数或组件设置的文件config-file中)[excluded]表示文档是否被elevator组件排除(在excludeIds参数)[json]表示JSON格式的文档(字符串)[xml]表示XML格式的文档(字符串)[subquery]表示以文档作子查询得到的文档列表[geo f=字段 w=格式]表示格式化地理数据,其中格式可以为WKT或GeoJSON[features]表示特性的值
有两种方法可以为参数提供局部参数:
- 在参数值前加上形如
{!局部参数=值 局部参数=值 局部参数=值} {!局部参数=值 局部参数=值 v=主参数值}
其中值带空格的话可以用单引号或双引号包围,并可以用${参数}引用其它参数的值,省略局部参数=则把参数视为type(用于参数解析器,默认为lucene)。
搜索语法
以下介绍几种常用的查询语法。
标准语法
当使用标准查询解析器(defType为lucene)时,查询语法与Lucene接近,功能丰富:
- 查询的基本组成单位是项
- 单词项由单词组成,其中可以使用能配符:
?匹配任何一个字符*匹配任意一列零个或多个字符
- 词组项由
"包围
- 单词项由单词组成,其中可以使用能配符:
- 可用
{(不包括下界)或[(包括下界)、下界、TO、上界、}(不包括上界)或](包括上界)表示范围查询 - 在项后加上
~和一个数的话表示进行模糊匹配,即匹配与项的编辑距离(对于单词项)不太远的词或与项中各单词没有相距太远的词组。 - 在项后加上
^和一个数的话表示项的重要性,这个数越大匹配这项的文档评分越高,不指定视为1。 - 在查询子句后加上
^=和一个数的话表示把匹配这子句文档的评分设为这个数(不理会其它因素)。 - 用
字段:项的形式表示要求结果的特定字段匹配项,特别地_val_字段可用于指定用作评分的函数结果。 - 可以使用布尔操作符组合查询:
AND或&&表示要求结果同时匹配两边的项NOT或!表示要求结果不匹配紧接的项OR或||表示要求结果至少匹配两边的项中一个+表示要求结果匹配紧接的项-表示要求结果不匹配紧接的项
- 可以用
(和)包围子句来形成子查询,以便控制逻辑运算的结合性或字段的作用范围。 - 如果需要查询的词含有
+、-、&&、||、!、(、)、{、}、[、]、^、"、~、*、?、:、/等有特殊意义的符号,可以在前面加上\来转义。 - 查询中可以用
/*与*/包围注释。
| 参数 | 用途 | 默认值 |
|---|---|---|
q |
查询 | 必须显式给出 |
q.op |
默认的查询操作符,可以是AND、OR |
OR |
df |
默认字段 | |
sow |
是否用空白把查询切分,然后分别处理各部分 | false |
DisMax语法
当使用DisMax查询解析器(defType为dismax)时,查询语法被大幅简化,只支持+、-、",其它标准的特殊字符都没有特殊意义,不太可能出现语法错误(奇数个"会当作没有词组),适合面向普通人。
| 参数 | 用途 | 默认值 |
|---|---|---|
q |
查询 | 必须显式给出 |
q.alt |
默认查询,即查询为空时执行此查询,通常用于匹配全部文档 | |
qf |
用于指定各字段的权重,由一些空格分隔的字段^重要性组成 |
|
mm |
可选的项中有多少要被匹配,可以是必须匹配的个数、-最多不匹配的个数、必须匹配的百分比%、-最多不匹配的百分比%、项数<有足够多项时的值(后半部分格式如前,类似有>,可用多次) |
100% |
pf |
用于指定各字段的权重(用于提高各单词出现在附近时的评分),由一些空格分隔的字段^重要性组成 |
|
ps |
词组中各单词最多能移动多远而仍视为匹配 | |
qs |
词组中各单词最多能移动多远而仍视为匹配(用于qf中) |
|
tie |
在多个字段都匹配时低分字段与最高分字段的影响力比 | 0.0 |
bq |
把此查询回到主查询后以影响评分(可指定多次) | |
bf |
类似于bq,只是会把{!func}插入到参数 |
扩展DisMax语法
当使用扩展DisMax查询解析器(defType为edismax)时,查询语法在DisMax语法的基础上进行了扩展:
- 标准语法中的布尔操作符如
AND(&&)、OR(||)、NOT - 可选择容许
and、or和子查询 - 在出现语法错误时智能转义
- 停用词仍然用于评分,并在全为停用词时保留全部
- 支持纯否定,如
+foo (-foo)会匹配所有文档
除了DisMax参数外还支持:
| 参数 | 用途 | 默认值 |
|---|---|---|
sow |
是否用空白把查询切分,然后分别处理各部分 | false |
mm.autoRelax |
是否在有子句被从部分字段移除(例如为停用词)后自动放宽必须匹配的子句数 | |
boost |
一个查询列表,结果的分数将会是它对些查询和主查询评分之积 | |
lowercaseOperators |
是否空话把and和or视为AND和OR |
false |
ps |
对于pf、pf2、pf3导致的词组查询,单词间的距离 |
|
pf2 |
与pf类似,只是对每三个单词形成的词组(2-gram) |
|
ps2 |
与ps类似,只是用pf2 |
同ps |
pf3 |
与pf类似,只是对每三个单词形成的词组(3-gram) |
|
ps3 |
与ps类似,只是用pf3 |
同ps |
stopwords |
是否去除停用词 | |
uf |
容许显式查询的字段(包括Solr内嵌子查询)列表(用空格分隔,可以用能配符) | * -_query_ |
其它语法
存在许多其它查询解析器用于不同用途,比如:
- 查询父文档、子、可达文档
- 查询类似文档
- 查询某项很少出现的文档
- 进行地理位置查询
- 要求前缀匹配
- 支持词组内用能配符
- 对结果进行连接
- 对前列结果按另一查询重新评分
- 用XML表达查询
高亮
在许多商用的搜索引擎中,结果页中各结果摘要中都会突出显示出现的搜索关键词,以便让用户理解为什么系统会提供这结果。在Solr查询中也可通过在参数hl.id中指定需要高亮的字段来做到这效果,例如curl 'http://localhost:8983/solr/fulltext/select?fl=id,date&hl.fl=title,content&hl=on&q=強积金'可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":18,
"params":{
"q":"強积金",
"hl":"on",
"fl":"id,date",
"hl.fl":"title,content",
"_":"1524202118322"}},
"response":{"numFound":1279,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/cap485B!zh-Hant-HK.assist.pdf",
"date":["2017-09-21T12:13:57Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485E!zh-Hant-HK.assist.pdf",
"date":["2017-04-22T09:55:46Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485A!zh-Hant-HK.assist.pdf",
"date":["2017-07-26T05:28:23Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485C!zh-Hant-HK.pdf",
"date":["2018-01-09T06:43:01Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485!zh-Hant-HK.assist.pdf",
"date":["2017-09-25T03:10:58Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485G!zh-Hant-HK.pdf",
"date":["2018-03-16T08:12:23Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485H!zh-Hant-HK.assist.pdf",
"date":["2017-04-22T10:06:26Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485F!zh-Hant-HK.pdf",
"date":["2018-03-16T08:10:04Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485I!zh-Hant-HK.assist.pdf",
"date":["2017-04-22T10:08:21Z"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap485D!zh-Hant-HK.assist.pdf",
"date":["2017-06-26T02:18:31Z"]}]
},
"highlighting":{
"/home/kwong/projects/translate/data/chi/cap485B!zh-Hant-HK.assist.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(豁免)規例》"],
"content":["補償基<em>金</em>為<em>強</em>制性公積<em>金</em>計劃所提供的保障內容。\n \n \n \n 4. 現有成員如選擇成為<em>強</em>制性公積<em>金</em>計劃的成員,其在有關職\n業退休註冊計劃下所會享有的權利。\n \n \n \n \n "]},
"/home/kwong/projects/translate/data/chi/cap485E!zh-Hant-HK.assist.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(臨時僱員供款)令》"],
"content":["經修訂的《<em>強</em>制性公積<em>金</em>計劃 ( 臨時僱員供款 ) 令》的適用情況\n \n \n \n 經本命令修訂的《<em>強</em>制性公積<em>金</em>計劃 ( 臨時僱員供款 ) 令》( 第 485 章,附屬法\n例 E),就於本命令的生效日期 # 當日或之後開始的供款期而適用。”。\n \n \n \n \n "]},
"/home/kwong/projects/translate/data/chi/cap485A!zh-Hant-HK.assist.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(一般)規例》"],
"content":["供款附加費的供款率 16-9\n \n 附表 1 計劃資<em>金</em>的投資 S1-1\n \n 附表 2 投資管控合約 S2-1\n \n 附表 3 保管協議的內容 S3-1\n \n 附表 4 罰款 S4-1\n \n 最後更新日期\n \n 26.6.2017\n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 一般 ) 規例》\n \n T-39\n \n 第 485A 章 \n \n \n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 一般 ) 規例》\n( 有關《2009 年<em>強</em>制性公積<em>金</em>計劃 ( 修訂 ) 條例》(2009 年第 11 號 ) 的過渡性及保留\n條文,請參看該條例第 24 條。)\n \n "]},
"/home/kwong/projects/translate/data/chi/cap485C!zh-Hant-HK.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(費用)規例》"],
"content":["經修訂的附表 1 第 12 項的適用範圍 1\n \n 附表 1 就《<em>強</em>制性公積<em>金</em>計劃條例》( 第\n485 章 ) 訂明的費用\n \n \n S1-1\n \n 附表 2 就《<em>強</em>制性公積<em>金</em>計劃 ( 一般 ) 規例》\n( 第 485 章,附屬法例 A) 訂明的費\n用\n \n S2-1\n \n 附表 3 就《<em>強</em>制性公積<em>金</em>計劃 ( 豁免 ) 規例》\n( 第 485 章,附屬法例 B) 訂明的費\n用\n \n S3-1\n \n 最後更新日期\n \n 1.1.2018\n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 費用 ) 規例》\n \n T-1\n \n 第 485C 章 \n \n \n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 費用 ) 規例》\n \n ( 第 485 章第 46 條 )\n(略去制定語式條文 ——2013年第 1號編輯修訂紀錄 )\n \n \n \n \n [1999 年 8 月 3 日 ]\n(格式變更 ——2013年第 1號編輯修訂紀錄 )\n \n 1. "]},
"/home/kwong/projects/translate/data/chi/cap485!zh-Hant-HK.assist.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃條例》"],
"content":["須備存獲豁免計劃的紀錄冊 1-33\n第 2 部\n \n <em>強</em>制性公積<em>金</em>計劃管理局\n \n 6. <em>強</em>制性公積<em>金</em>計劃管理局的設立 2-1\n \n 6A. "]},
"/home/kwong/projects/translate/data/chi/cap485G!zh-Hant-HK.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃規則》"],
"content":["(廢除 ) 9\n \n 最後更新日期\n \n 25.4.2013\n \n 《<em>強</em>制性公積<em>金</em>計劃規則》\n \n T-1\n \n 第 485G 章 \n \n \n \n 《<em>強</em>制性公積<em>金</em>計劃規則》\n \n ( 第 485 章第 47 條 )\n(略去制定語式條文 ——2013年第 1號編輯修訂紀錄 )\n \n \n \n \n [2000 年 12 月 1 日 ]\n(格式變更 ——2013年第 1號編輯修訂紀錄 )\n \n 1. "]},
"/home/kwong/projects/translate/data/chi/cap485H!zh-Hant-HK.assist.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(補償申索)規則》"],
"content":["管理局須向原訟法庭申請指示 3\n \n 最後更新日期\n \n 1.12.2000\n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 補償申索 ) 規則》\n \n T-1\n \n 第 485H 章 \n \n \n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 補償申索 ) 規則》\n( 第 485 章第 17(B) 條 )\n \n \n \n \n [2000 年 12 月 1 日 ]\n \n 1. "]},
"/home/kwong/projects/translate/data/chi/cap485F!zh-Hant-HK.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(指明特准限期)公告》"],
"content":["最後更新日期\n \n 12.11.2015\n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 指明特准限期 ) 公告》\n \n 1 \n第 485F 章 第 1 條\n \n 經核證文本 \n \n \n \n 2. "]},
"/home/kwong/projects/translate/data/chi/cap485I!zh-Hant-HK.assist.pdf":{
"title":["《<em>強</em>制性公積<em>金</em>計劃(清盤)規則》"],
"content":["原訟法庭可命令將註冊計劃清盤 3\n \n 最後更新日期\n \n 1.12.2000\n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 清盤 ) 規則》\n \n T-1\n \n 第 485I 章 \n \n \n \n 《<em>強</em>制性公積<em>金</em>計劃 ( 清盤 ) 規則》\n( 第 485 章第 34A 條 )\n \n \n \n \n [2000 年 12 月 1 日 ]\n \n 1. "]},
"/home/kwong/projects/translate/data/chi/cap485D!zh-Hant-HK.assist.pdf":{
"title":["《〈<em>強</em>制性公積<em>金</em>計劃(豁免)規例〉(根據第5及16條指明日期)公告》"],
"content":["為施行《<em>強</em>制性公積<em>金</em>計劃 ( 豁免 ) 規例》第 5 及 16 條,現指\n明 2000 年 5 月 4 日為該兩條所指的指明日期。\n \n 最後更新日期\n \n 3.3.2000\n \n 《〈<em>強</em>制性公積<em>金</em>計劃 ( 豁免 ) 規例〉( 根據第 5 及 16 條指明日期 ) 公告》\n \n 1 \n第 485D 章 第 1 條 \n \n \n \t 第485D章 \n \t 賦權條文 \n\t 第1條 \n \n \n "]}}}
我们看到现在返回的JSON体中多了一个字段highlighting,它是一个映射表,把结果ID映射到另一个映射表,这映射表把字段名映射到高亮片段,高亮片段中关键词被<em>和</em>包围。
| 参数 | 用途 | 默认值 |
|---|---|---|
hl |
是否所有高亮 | false |
hl.method |
高亮方法:unified或original或fastVector |
original |
hl.fl |
需要高亮的字段列表(用逗号或空格分隔),可以用*通配 |
df参数值 |
hl.q |
高亮的查询 | q参数值 |
hl.qparser |
用于hl.q的查询解析器 |
defType参数值 |
hl.requireFieldMatch |
只高亮与所查询字段吻合的 | false |
hl.usePhraseHighlighter |
是否只高亮整个词组而非它的组成部分 | true |
hl.highlightMultiTerm |
是否高亮通配查询 | true |
hl.snippets |
每个字段最多的高亮片段数 | 1 |
hl.fragsize |
高亮内容的预期长度 | 100 |
hl.tag.pre |
高亮内容开始处插入的记号 | <em> |
hl.tag.post |
高亮内容结束处插入的记号 | </em> |
hl.encoder |
高度内容编码器,如html表示进行HTML转义 |
|
hl.maxAnalyzedChars |
为寻找高亮片段所分析的最多字数 | 51200 |
以下介绍各高亮方法的区别:
unified是最新的最灵活的,目前已经是官方推荐。它既可以在查询时从stored文本寻找高亮,对于storeOffsetsWithPositions字段或有项向量的字段还可以用索引时信息加速。original是Lucene原始的高亮器,可以在底层定制,但不支持断词或断句。它既可以在查询时从stored文本寻找高亮,对于有项向量的字段还可以用索引时信息加速,但仍然比其它方法稍慢一点。fastVector支持多颜色高亮,但对于复杂查询可能不准确。它要求字段有项向量(termVectors、termPositions、termOffsets),这比storeOffsetsWithPositions字段占用更多空间。
不同高亮方法有不同的参数以下以unified为例:
| 参数 | 用途 | 默认值 |
|---|---|---|
hl.offsetSource |
位置来源:ANALYSIS、POSTINGS、POSTINGS_WITH_TERM_VECTORS或TERM_VECTORS |
自动 |
hl.tag.ellipsis |
把多个片段用这字符串连接起来 | |
hl.defaultSummary |
找不到高亮片段时用文本的开首 | false |
hl.score.k1 |
BM25频率正规化参数,0表示只与匹配的项数有关 | 1.2 |
hl.score.b |
BM25长度正规化参数,0表示忽略长度 | 0.75 |
hl.score.pivot |
BM25平均片段长度 |
87 |
hl.bs.language |
文档划分基于的语言 | |
hl.bs.country |
文档划分基于的地区 | |
hl.bs.variant |
文档划分基于的变种 | |
hl.bs.type |
文档划分方法,用于使整个单位显示在高亮片段中,可以为SEPARATOR、SENTENCE、WORD、CHARACTER、LINE、WHOLE |
SENTENCE |
hl.bs.separator |
文本分隔符 |
分片
在许多电商搜索引擎中,结果页中经常推荐一些分类并提示分类数,以便让用户细化查询。
| 参数 | 用途 | 默认值 |
|---|---|---|
facet |
是否启用分片 | false |
facet.query |
需要分片的查询 |
字段分片
在Solr查询中也可通过在参数facet.field中指定需要分片的字段来做到按字段中的项创建分类的效果,例如curl 'http://localhost:8983/solr/fulltext/select?facet.field=content_type&facet=on&fl=id,date&q=*:*&rows=0'
可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1,
"params":{
"q":"*:*",
"facet.field":"content_type",
"fl":"id,date",
"rows":"0",
"facet":"on",
"_":"1524202118322"}},
"response":{"numFound":11234,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"content_type":[
"text/html; charset=GB2312",8949,
"application/pdf",2259,
"text/html; charset=ISO-8859-1",15]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}}
我们看到现在返回的JSON体中多了一个字段facet_counts,它是一个映射表:
facet_fields字段中给出了各字段中各个项的计数
| 参数 | 用途 | 默认值 |
|---|---|---|
facet.field |
需分片字段(可多次指定) | |
facet.prefix |
只返回项有指定前缀的片 | |
facet.contains |
只返回项带一个子字符串的片 | |
facet.contains.ignoreCase |
是否在facet.contains进行匹配时忽略大小写 |
|
facet.matches |
只返回项匹配一个正则表达式的片 | |
facet.sort |
片的排序,可以是count或index |
facet.limit正时为count否则index |
facet.limit |
最多返回的片数,负表示不限 | 100 |
facet.offset |
返回的首个片的偏移 | 0 |
facet.mincount |
只返回至少有这个数量的文档的片 | 0 |
facet.missing |
是否返回一个由缺失字段的文档组成的片 | false |
facet.method |
分片算法:enum(枚举字段的项,适合相异项少的多值字段)、fc(把缓存中匹配查询的文档的对应项数向量加起来,适合字段有很多项但每个文档只有很少项时)、fcs(对单值字符串字段分块地分片,容许多线程,适合索引快速更新时) |
fc(除非是布尔字段且facet.exists=true) |
facet.enum.cache.minDf |
对项启用过滤缓存的最少匹配文档数 | 0 |
facet.exists |
把非空分片的计数都设为1,从而节省计数的开销,只适用于非前缀树字段(特别地不能用于字符串) | |
facet.excludeTerms |
要求不返回的项列表 | |
facet.overrequest.count和facet.overrequest.ratio |
在数据分布在多个结点时,只查询每个结点的首facet.overrequest.count+facet.overrequest.ratio*facet.limit个项 | 10和1.5 |
facet.threads |
最大线程数,0表示用主查询线程 | 0 |
决策树分片
有时我们希望按一个字段的分片再对另一个字段分片。例如curl 'http://localhost:8983/solr/fulltext/select?facet.pivot=content_type,subject&facet=on&q=*:*&rows=0'可能返回:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1,
"params":{
"q":"*:*",
"facet.pivot":"content_type,subject",
"rows":"0",
"facet":"on",
"_":"1524202118322"}},
"response":{"numFound":11234,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"content_type,subject":[{
"field":"content_type",
"value":"text/html; charset=GB2312",
"count":8949},
{
"field":"content_type",
"value":"application/pdf",
"count":2259,
"pivot":[{
"field":"subject",
"value":"legislation",
"count":2258}]},
{
"field":"content_type",
"value":"text/html; charset=ISO-8859-1",
"count":15}]}}}
| 参数 | 用途 | 默认值 |
|---|---|---|
facet.pivot |
需要分片的字段列表(用,分隔) |
|
facet.pivot.mincount |
只列出文档数超过这个数的分类 | 1 |
范围分片
在许多电商搜索引擎中,结果页中经常推荐一些按价格范围的分类并提示分类数。在Solr查询中也可以实现按值范围分类的效果,例如curl 'http://localhost:8983/solr/fulltext/select?facet.range.end=NOW/DAY&facet.range.gap=+3MONTHS&facet.range.other=all&facet.range.start=NOW/DAY-2YEARS&facet.range=date&facet=on&q=*:*&rows=0'
可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":6,
"params":{
"facet.range":"date",
"q":"*:*",
"facet.range.gap":"+3MONTHS",
"facet.range.other":"all",
"rows":"0",
"facet":"on",
"facet.range.start":"NOW/DAY-2YEARS",
"_":"1524284370752",
"facet.range.end":"NOW/DAY"}},
"response":{"numFound":11234,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"date":{
"counts":[
"2016-04-21T00:00:00Z",0,
"2016-07-21T00:00:00Z",0,
"2016-10-21T00:00:00Z",109,
"2017-01-21T00:00:00Z",1074,
"2017-04-21T00:00:00Z",447,
"2017-07-21T00:00:00Z",199,
"2017-10-21T00:00:00Z",257,
"2018-01-21T00:00:00Z",173],
"gap":"+3MONTHS",
"before":8948,
"after":0,
"between":2259,
"start":"2016-04-21T00:00:00Z",
"end":"2018-04-21T00:00:00Z"}},
"facet_intervals":{},
"facet_heatmaps":{}}}
| 参数 | 用途 | 默认值 |
|---|---|---|
facet.range |
需要分片的字段,可指定多次 | |
facet.range.start |
分片字段项的下界 | |
f.字段.facet.range.start |
特定分片字段项的下界 | |
facet.range.end |
分片字段项的上界 | |
f.字段.facet.range.end |
特定分片字段项的上界 | |
facet.range.gap |
每个范围的长度 | |
facet.range.hardend |
是否让最后一个区间的上界准确地如facet.range.end(否则保持最后区间长度为facet.range.gap) |
false |
f.字段.facet.range.hardend |
同上,只是只适用于特定字段 | |
facet.range.include |
边界处理方法:lower(所有区间包括其下界)、upper(所有区间包括其上界)、edge(首个区间包括下界,最后一个区间包括其上界)、outer (before和after包括它的界)、all,可以指定多次,部分选项可能造成边界处重复计数 |
lower |
f.字段.facet.range.include |
同上,只是只适用于特定字段 | |
facet.range.other |
额外计数:none、before(小于首区间下界的)、after(大于末区间上界的)、between(首区间下界与末区间上界之间的)、all,可指定多次 |
|
f.字段.facet.range.other |
同上,只是只适用于特定字段 | |
facet.range.method |
分片算法:filter(对每个区间分别建立过滤再与主查询结果集求交,可用过滤缓存加速)、dv(迭代主查询的结果集,可用过滤缓存或docValues加速,不支持日期范围字段和group.facets) |
区间分片
在范围分片中每个范围区间有相同的长度,但有时我们希望更灵活。例如curl 'http://localhost:8983/solr/fulltext/select?facet.interval.set=(2000-01-01T00:00:00Z,2010-01-01T00:00:00Z]&facet.interval.set=(2010-01-01T00:00:00Z,*]&facet.interval=date&facet=on&q=*:*&rows=0'可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":2,
"params":{
"q":"*:*",
"facet.interval":"date",
"rows":"0",
"facet":"on",
"facet.interval.set":["(2000-01-01T00:00:00Z,2010-01-01T00:00:00Z]",
"(2010-01-01T00:00:00Z,*]"],
"_":"1524284370752"}},
"response":{"numFound":11234,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{},
"facet_intervals":{
"date":{
"(2000-01-01T00:00:00Z,2010-01-01T00:00:00Z]":8948,
"(2010-01-01T00:00:00Z,*]":2259}},
"facet_heatmaps":{}}}
| 参数 | 用途 | 默认值 |
|---|---|---|
facet.interval |
需要分片的字段(可指定多次) | |
facet.interval.set |
区间,由(或[、下限(没有下限则*)、,、上限(没有上限则*)、)或]组成 |
|
f.字段.facet.interval.set |
同上,但只适用于特定字段 |
地理位置分片
对于地理位置字段,可以把一个区域分为一些方格,然后计算落在每个方格的结果数。形如:
{gridLevel=6,columns=64,rows=64,minX=-180.0,maxX=180.0,minY=-90.0,maxY=90.0,
counts_ints2D=[[0, 0, 2, 1, ....],[1, 1, 3, 2, ...],...]}
| 参数 | 用途 | 默认值 |
|---|---|---|
facet.heatmap |
分片字段 | |
facet.heatmap.geom |
所关心的矩形区域 | ["-180 -90" TO "180 90"] |
facet.heatmap.gridLevel |
方格大小 | 通过distErrPct或distErr计算 |
facet.heatmap.distErrPct |
0.15 | |
facet.heatmap.distErr |
方格距离误差 | |
facet.heatmap.format |
ints2D或png |
ints2D |
结果分组
字段
一个简单方法是按在字段上的取值分组,例如curl 'http://localhost:8983/solr/techproducts/select?group.field=inStock&group.limit=3&group=true&q=*:*'可能返回:
{
"responseHeader":{
"status":0,
"QTime":0,
"params":{
"q":"*:*",
"group.limit":"3",
"group.field":"inStock",
"_":"1524385596614",
"group":"true"}},
"grouped":{
"inStock":{
"matches":32,
"groups":[{
"groupValue":true,
"doclist":{"numFound":17,"start":0,"docs":[
{
"id":"GB18030TEST",
"name":"Test with some GB18030 encoded characters",
"features":["No accents here",
"这是一个功能",
"This is a feature (translated)",
"这份文件是很有光泽",
"This document is very shiny (translated)"],
"price":0.0,
"price_c":"0.0,USD",
"inStock":true,
"_version_":1598433930786111488,
"price_c____l_ns":0},
{
"id":"TWINX2048-3200PRO",
"name":"CORSAIR XMS 2GB (2 x 1GB) 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) Dual Channel Kit System Memory - Retail",
"manu":"Corsair Microsystems Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 2, 2-3-3-6 timing, 2.75v, unbuffered, heat-spreader"],
"price":185.0,
"price_c":"185.00,USD",
"popularity":5,
"inStock":true,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|6.0 memory|3.0",
"_version_":1598433930916134912,
"price_c____l_ns":18500},
{
"id":"VS1GB400C3",
"name":"CORSAIR ValueSelect 1GB 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) System Memory - Retail",
"manu":"Corsair Microsystems Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"price":74.99,
"price_c":"74.99,USD",
"popularity":7,
"inStock":true,
"store":"37.7752,-100.0232",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|4.0 memory|2.0",
"_version_":1598433930970660864,
"price_c____l_ns":7499}]
}},
{
"groupValue":false,
"doclist":{"numFound":4,"start":0,"docs":[
{
"id":"EN7800GTX/2DHTV/256M",
"name":"ASUS Extreme N7800GTX/2DHTV (256 MB)",
"manu":"ASUS Computer Inc.",
"manu_id_s":"asus",
"cat":["electronics",
"graphics card"],
"features":["NVIDIA GeForce 7800 GTX GPU/VPU clocked at 486MHz",
"256MB GDDR3 Memory clocked at 1.35GHz",
"PCI Express x16",
"Dual DVI connectors, HDTV out, video input",
"OpenGL 2.0, DirectX 9.0"],
"weight":16.0,
"price":479.95,
"price_c":"479.95,USD",
"popularity":7,
"store":"40.7143,-74.006",
"inStock":false,
"manufacturedate_dt":"2006-02-13T00:00:00Z",
"_version_":1598433930985340928,
"price_c____l_ns":47995},
{
"id":"100-435805",
"name":"ATI Radeon X1900 XTX 512 MB PCIE Video Card",
"manu":"ATI Technologies",
"manu_id_s":"ati",
"cat":["electronics",
"graphics card"],
"features":["ATI RADEON X1900 GPU/VPU clocked at 650MHz",
"512MB GDDR3 SDRAM clocked at 1.55GHz",
"PCI Express x16",
"dual DVI, HDTV, svideo, composite out",
"OpenGL 2.0, DirectX 9.0"],
"weight":48.0,
"price":649.99,
"price_c":"649.99,USD",
"popularity":7,
"inStock":false,
"manufacturedate_dt":"2006-02-13T00:00:00Z",
"store":"40.7143,-74.006",
"_version_":1598433930989535232,
"price_c____l_ns":64999},
{
"id":"F8V7067-APL-KIT",
"name":"Belkin Mobile Power Cord for iPod w/ Dock",
"manu":"Belkin",
"manu_id_s":"belkin",
"cat":["electronics",
"connector"],
"features":["car power adapter, white"],
"weight":4.0,
"price":19.95,
"price_c":"19.95,USD",
"popularity":1,
"inStock":false,
"store":"45.18014,-93.87741",
"manufacturedate_dt":"2005-08-01T16:30:25Z",
"_version_":1598433931016798208,
"price_c____l_ns":1995}]
}},
{
"groupValue":null,
"doclist":{"numFound":11,"start":0,"docs":[
{
"id":"adata",
"compName_s":"A-Data Technology",
"address_s":"46221 Landing Parkway Fremont, CA 94538",
"_version_":1598433931026235392},
{
"id":"apple",
"compName_s":"Apple",
"address_s":"1 Infinite Way, Cupertino CA",
"_version_":1598433931027283968},
{
"id":"asus",
"compName_s":"ASUS Computer",
"address_s":"800 Corporate Way Fremont, CA 94539",
"_version_":1598433931027283969}]
}}]}}}
| 参数 | 用途 | 默认值 |
|---|---|---|
group |
是否启用结果分组 | |
group.field |
分组依据的字段,必须是单值的基于字符串的字段 | |
group.func |
按函数查询分组 | |
group.query |
返回一个满足这查询的分组 | |
rows |
返回的组数 | 10 |
start |
返回的首个组的序号 | |
group.limit |
每个分组的结果数 | 1 |
group.offset |
每个分组中首个结果的序号 | |
sort |
组排序依据 | score desc |
group.sort |
组内排序依据 | 同sort |
group.format |
simple(扁平)或grouped |
|
group.main |
是否把首个字段分组命令的结果主结果 | |
group.ngroups |
返回组数 | false |
group.truncate |
分片数据基于每组中最相关文档 | false |
group.facet |
是否计算分组的分片 | false |
group.cache.percent |
组缓存,只对布尔、通配、模糊查询有利 | 0 |
聚类
按字段的值来分组有时显得太严格,这时可能应该用文本聚类算法进行模糊的分类。
要使用结果聚类需要在启动Solr时加上-Dsolr.clustering.enabled=true命令行选项,并且确保solrconfig.xml中有类似以下的内容:
<lib dir="${solr.install.dir:../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../..}/dist/" regex="solr-clustering-\d.*\.jar" />
<searchComponent name="clustering" class="solr.clustering.ClusteringComponent">
<!-- Lingo 聚类算法 -->
<lst name="engine">
<str name="name">lingo</str>
<str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str>
</lst>
<!-- STC 聚类德法 -->
<lst name="engine">
<str name="name">stc</str>
<str name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm</str>
</lst>
</searchComponent>
<requestHandler name="/clustering" class="solr.SearchHandler">
<lst name="defaults">
<!-- 启用聚类 -->
<bool name="clustering">true</bool>
<!-- 对搜索结果聚类 -->
<bool name="clustering.results">true</bool>
<!-- 其它常用选项有
clustering.engine(聚类算法)、
clustering.collection(对索引聚类)
carrot.produceSummary(只对高亮片段而非完整字段聚类)、
carrot.fragSize(高亮长度,默认同hl.fragsize)、
carrot.summarySnippets(高亮片段数,默认同hl.snippets )
carrot.lang(ISO 639-1语言代码)
-->
<!-- 逻辑字段对应到物理字段 -->
<str name="carrot.url">id</str>
<str name="carrot.title">doctitle</str>
<str name="carrot.snippet">content</str>
<!-- 配置其它请求处理器参数,我们对前100个结果聚类 -->
<str name="rows">100</str>
<str name="fl">*,score</str>
</lst>
<!-- 把clustering加到搜索组件列表的最后 -->
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>
现在进行GET请求http://localhost:8983/solr/techproducts/clustering?fl=%22%22&q=*:*可能得到以下样子的结果:
{
"responseHeader":{
"status":0,
"QTime":7},
"response":{"numFound":32,"start":0,"docs":[
{
"id":"GB18030TEST"},
{
"id":"TWINX2048-3200PRO"},
{
"id":"VS1GB400C3"},
{
"id":"VDBDB1A16"},
{
"id":"3007WFP"},
{
"id":"EN7800GTX/2DHTV/256M"},
{
"id":"100-435805"},
{
"id":"SP2514N"},
{
"id":"6H500F0"},
{
"id":"MA147LL/A"},
{
"id":"USD"},
{
"id":"EUR"},
{
"id":"GBP"},
{
"id":"NOK"},
{
"id":"0579B002"},
{
"id":"F8V7067-APL-KIT"},
{
"id":"IW-02"},
{
"id":"SOLR1000"},
{
"id":"adata"},
{
"id":"apple"},
{
"id":"asus"},
{
"id":"ati"},
{
"id":"belkin"},
{
"id":"canon"},
{
"id":"corsair"},
{
"id":"dell"},
{
"id":"maxtor"},
{
"id":"samsung"},
{
"id":"viewsonic"},
{
"id":"9885A004"},
{
"id":"VA902B"},
{
"id":"UTF8TEST"}]
},
"clusters":[{
"labels":["DDR"],
"score":5.051807616210845,
"docs":["TWINX2048-3200PRO",
"VS1GB400C3",
"VDBDB1A16"]},
{
"labels":["iPod"],
"score":12.401261540209301,
"docs":["MA147LL/A",
"F8V7067-APL-KIT",
"IW-02"]},
{
"labels":["CORSAIR"],
"score":3.1631328487963533,
"docs":["TWINX2048-3200PRO",
"VS1GB400C3"]},
{
"labels":["Canon"],
"score":6.684450795059629,
"docs":["0579B002",
"9885A004"]},
{
"labels":["Encoded Characters"],
"score":10.209296145491782,
"docs":["GB18030TEST",
"UTF8TEST"]},
{
"labels":["Hard Drive"],
"score":17.005309034358238,
"docs":["SP2514N",
"6H500F0"]},
{
"labels":["Video"],
"score":9.508699485211157,
"docs":["100-435805",
"MA147LL/A"]},
{
"labels":["Other Topics"],
"score":0.0,
"other-topics":true,
"docs":["3007WFP",
"EN7800GTX/2DHTV/256M",
"USD",
"EUR",
"GBP",
"NOK",
"SOLR1000",
"adata",
"apple",
"asus",
"ati",
"belkin",
"canon",
"corsair",
"dell",
"maxtor",
"samsung",
"viewsonic",
"VA902B"]}]}
我们看到在clusters字段的每个类中给出了一个标签(类名和类中的文档)
类似结果
许多电商平台都有“类似产品”,其中一个实现方式为把产品描述中词频类似的当成类似产品。例如curl 'http://localhost:8983/solr/fulltext/select?df=title&fl=id,title&mlt.fl=content&mlt=true&q=%22%E5%9F%BA%E6%9C%AC%E6%B3%95%22&rows=5&sort=id%20asc'可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":17,
"params":{
"q":"\"基本法\"",
"df":"title",
"mlt":"true",
"fl":"id,title",
"mlt.fl":"content",
"sort":"id asc",
"rows":"5",
"_":"1524284370752"}},
"response":{"numFound":16,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國香港特別行政區基本法(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A102!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》附件三所列全國性法律增減的決定(1997年7月1日第八屆全國人民代表大會常務委員會第二十六次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A103!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於增加《中華人民共和國香港特別行政區基本法》附件三所列全國性法律的決定(1998年11月4日通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A104!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會關於《中華人民共和國香港特別行政區基本法》的決定 (1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A105!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》英文本的決定(1990年6月28日通過)"]}]
},
"moreLikeThis":{
"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf":{"numFound":11019,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A301!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國政府和大不列顛及北愛爾蘭聯合王國政府關於香港問題的聯合聲明"]},
{
"id":"/home/kwong/projects/translate/data/chi/A403!zh-Hant-HK.assist.pdf",
"title":["1997年全國性法律公布(第2號)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A1!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國憲法(1982年12月4日第五屆全國人民代表大會第五次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A203!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會關於批准香港特別行政區基本法起草委員會關於設立全國人民代表大會常務委員會香港特別行政區基本法委員會的建議的決定(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/cap558H!zh-Hant-HK.pdf",
"title":["《國際組織(特權及豁免權)(海牙國際私法會議亞太區域辦事處)令》"]}]
},
"/home/kwong/projects/translate/data/chi/A102!zh-Hant-HK.assist.pdf":{"numFound":11009,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國香港特別行政區基本法(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A206!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於根據《中華人民共和國香港特別行政區基本法》第一百六十條處理香港原有法律的決定(1997年2月23日第八屆全國人民代表大會常務委員會第二十四次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A401!zh-Hant-HK.pdf",
"title":["《國旗及國徽條例》"]},
{
"id":"/home/kwong/projects/translate/data/chi/A301!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國政府和大不列顛及北愛爾蘭聯合王國政府關於香港問題的聯合聲明"]},
{
"id":"/home/kwong/projects/translate/data/chi/A5!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國憲法修正案 (2004年3月14日第十屆全國人民代表大會第二次會議通過)"]}]
},
"/home/kwong/projects/translate/data/chi/A103!zh-Hant-HK.assist.pdf":{"numFound":10802,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A102!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》附件三所列全國性法律增減的決定(1997年7月1日第八屆全國人民代表大會常務委員會第二十六次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國香港特別行政區基本法(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A109!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於增加《中華人民共和國香港特別行政區基本法》附件三所列全國性法律的決定(2005年10月27日通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A206!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於根據《中華人民共和國香港特別行政區基本法》第一百六十條處理香港原有法律的決定(1997年2月23日第八屆全國人民代表大會常務委員會第二十四次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A114!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》第十三條第一款和第十九條的解釋(2011年8月26日第十一屆全國人民代表大會常務委員會第二十二次會議通過)"]}]
},
"/home/kwong/projects/translate/data/chi/A104!zh-Hant-HK.assist.pdf":{"numFound":11020,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國香港特別行政區基本法(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A202!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會關於香港特別行政區第一屆政府和立法會產生辦法的決定(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A203!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會關於批准香港特別行政區基本法起草委員會關於設立全國人民代表大會常務委員會香港特別行政區基本法委員會的建議的決定(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A201!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會關於設立香港特別行政區的決定(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A107!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於《中華人民共和國香港特別行政區基本法》附件一第七條和附件二第三條的解釋(2004年4月6日第十屆全國人民代表大會常務委員會第八次會議通過)"]}]
},
"/home/kwong/projects/translate/data/chi/A105!zh-Hant-HK.assist.pdf":{"numFound":11012,"start":0,"docs":[
{
"id":"/home/kwong/projects/translate/data/chi/A101!zh-Hant-HK.assist.pdf",
"title":["中華人民共和國香港特別行政區基本法(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A206!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於根據《中華人民共和國香港特別行政區基本法》第一百六十條處理香港原有法律的決定(1997年2月23日第八屆全國人民代表大會常務委員會第二十四次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A601!zh-Hant-HK.pdf",
"title":["《香港回歸條例》"]},
{
"id":"/home/kwong/projects/translate/data/chi/A110!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會常務委員會關於批准《中華人民共和國香港特別行政區基本法附件一香港特別行政區行政長官的產生辦法修正案》的決定(2010年8月28日第十一屆全國人民代表大會常務委員會第十六次會議通過)"]},
{
"id":"/home/kwong/projects/translate/data/chi/A203!zh-Hant-HK.assist.pdf",
"title":["全國人民代表大會關於批准香港特別行政區基本法起草委員會關於設立全國人民代表大會常務委員會香港特別行政區基本法委員會的建議的決定(1990年4月4日第七屆全國人民代表大會第三次會議通過)"]}]
}}}
| 参数 | 用途 | 默认值 |
|---|---|---|
mlt |
是否启用类似结果 | false |
mlt.fl |
用于计算相似度的字段 | |
mlt.count |
每个文档返回的类似结果数 | 5 |
mlt.mintf |
引起注意的最低项频 | |
mlt.mindf |
只考虑出现在至少这么多个文档的词 | |
mlt.maxdf |
只考虑出现在至多这么多个文档的词 | |
mlt.maxdfpct |
只考虑出现在至多这个百分比个文档的词 | |
mlt.minwl |
词引起注意的最小长度 | |
mlt.maxwl |
词引起注意的最大长度 | |
mlt.maxqt |
生成查询包含的最大项数 | |
mlt.maxntp |
每个样本文档最多解析的单词数 | |
mlt.boost |
是否按有趣项相关性提升查询 | |
mlt.qf |
同DisMax中qf参数,但其中字段必须出现在mlt.fl |
数据分析
项频
我们可以统计不同项出现的文档数。例如curl 'http://localhost:8983/solr/fulltext/select?q=*:*&rows=0&terms.fl=content&terms.stats=true&terms=true'可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":52,
"params":{
"q":"*:*",
"terms.stats":"true",
"terms":"true",
"terms.fl":"content",
"rows":"0",
"_":"1524284370752"}},
"response":{"numFound":11234,"start":0,"docs":[]
},
"terms":{
"content":[
"文",11006,
"例",11003,
"的",11001,
"更",10981,
"新",10978,
"所",10894,
"及",10873,
"6",10872,
"定",10817,
"有",10793]},
"indexstats":{
"numDocs":11234}}
| 参数 | 用途 | 默认值 |
|---|---|---|
terms |
是否启用项组件 | false |
terms.fl |
用于获取项的字段,可多次指定 | |
terms.list |
要取得文档数的项列表(用,分隔) |
|
terms.limit |
返回的最大项数,负表示不限,不提供这参数则要提供terms.upper |
|
terms.lower |
停止于哪个项,前面的项不再返回 | |
terms.lower.incl |
是否包括上述的停止项 | true |
terms.mincount |
返回项对应的最少文档数 | |
terms.maxcount |
返回项对应的最大文档数,负表示不限 | -1 |
terms.prefix |
返回项的前缀 | |
terms.raw |
是否返回原始字符(即使对人不可读) | |
terms.regex |
项满足的正则表达式 | |
terms.regex.flag |
正则表达式模式:case_insensitive、comments、multiline、literal、dotall、unicode_case、canon_eq、unix_lines |
|
terms.stats |
是否返回索引统计 | |
terms.sort |
排序依据:count或index |
|
terms.ttf |
是否返回总项频 | |
terms.upper |
停止于哪个项,后面的项不再返回 | |
terms.upper.incl |
是否包括上述的停止项 | false |
描述性统计量
我们可以取得关于字段项的描述性统计量。例如curl 'http://localhost:8983/solr/fulltext/select?q=*:*&rows=0&stats.field=date&stats=true'可能得到类似下面的结果:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":3,
"params":{
"q":"*:*",
"stats":"true",
"rows":"0",
"_":"1524284370752",
"stats.field":"date"}},
"response":{"numFound":11234,"start":0,"docs":[]
},
"stats":{
"stats_fields":{
"date":{
"min":"2001-09-18T15:35:44Z",
"max":"2018-03-28T04:30:11Z",
"count":11207,
"missing":27,
"sum":1.3889295079897E16,
"mean":"2009-04-10T05:24:03.981Z",
"sumOfSquares":1.740206144832493E28,
"stddev":1.2969299676900275E11}}}}
| 参数 | 用途 | 默认值 |
|---|---|---|
stats |
是否返回统计信息 | false |
stats.field |
需统计的字段,可多次指定 |
更深入的处理
在solrconfig.xml中启用analytics:
<searchComponent name="analytics" class="org.apache.solr.handler.component.AnalyticsComponent" />
<requestHandler name="/select" class="solr.SearchHandler">
<arr name="last_components">
<str>analytics</str>
</arr>
</requestHandler>
<requestHandler name="/analytics" class="org.apache.solr.handler.AnalyticsHandler" />
然后就可以把分析请求通过analytics参数传入:
curl --data-urlencode '
analytics={
"functions": {
"sale()": "mult(price,quantity)"},
"expressions" : {
"max_sale" : "max(sale())",
"med_sale" : "median(sale())"},
"groupings" : {
"sales" : {
"expressions" : {
"stddev_sale" : "stddev(sale())",
"min_price" : "min(price)",
"max_quantity" : "max(quantity)"},
"facets" : {
"category" : {
"type" : "value",
"expression" : "fill_missing(category, 'No Category')",
"sort" : {
"criteria" : [
{
"type" : "expression",
"expression" : "min_price",
"direction" : "ascending"},
{
"type" : "facetvalue",
"direction" : "descending"}],
"limit" : 10}},
"temps" : {
"type" : "query",
"queries" : {
"hot" : "temp:[90 TO *]",
"cold" : "temp:[* TO 50]"}}}}}}'
http://localhost:8983/solr/sales/select?q=*:*&wt=json&rows=0
更强大的分析可能需要用到流语言,它可以批处理式地高效完成各种任务,例如:
curl --data-urlencode 'expr=search(enron_emails,
q="from:1800flowers*",
fl="from, to",
sort="from asc",
qt="/export")' http://localhost:8983/solr/enron_emails/stream
可能导致返回:
{"result-set":{"docs":[
{"from":"1800flowers.133139412@s2u2.com","to":"lcampbel@enron.com"},
{"from":"1800flowers.93690065@s2u2.com","to":"jtholt@ect.enron.com"},
{"from":"1800flowers.96749439@s2u2.com","to":"alewis@enron.com"},
{"from":"1800flowers@1800flowers.flonetwork.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@1800flowers.flonetwork.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@1800flowers.flonetwork.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@1800flowers.flonetwork.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@1800flowers.flonetwork.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@shop2u.com","to":"ebass@enron.com"},
{"from":"1800flowers@shop2u.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@shop2u.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@shop2u.com","to":"lcampbel@enron.com"},
{"from":"1800flowers@shop2u.com","to":"ebass@enron.com"},
{"from":"1800flowers@shop2u.com","to":"ebass@enron.com"},
{"EOF":true,"RESPONSE_TIME":33}]}
}
结语
作为一个功能相当完整的搜索服务器软件,Solr有众多的配置选项和扩展方式,它们对搜索质量的影响需要长时间实际经验才能体会到。另外,对于我们没有介绍的众多Solr特性请参阅Solr手册。