基于笔划提取的脱机手写数学公式识别
手写体识别传统上被分为联机识别和脱机识别,前者识别动态的笔迹而后者识别静态的图片。与联机识别相比,由于缺乏动态信息和存在背景噪声,脱机识别的准确度通常较低,同时往往占用更多资源。于是,把脱机识别问题转化为联机识别问题是一个有吸引力的想法。本文以由于具有紧凑的二维结构而极具挑战性的数学公式识别问题为例,探讨了基于笔划提取的脱机手写识别的可行性和实用性,这方法夺得了国际性权威竞赛CROHME 2019中有关任务的季军。
为什么要识别数学公式
数学公式是在各种手写和印刷文档中常见的信息载体,如何充分地利用数学公式中的价值是一个有意义的问题。由于紧凑的二维结构有助于简明地表达一些概念,数学公式在经管、科学、工程和其它领域中都十分重要。为了提高数学公式的可发现性,把数学公式电子化是很有必要的,因为这有助于长时间保存和传播。进一步把数学公式结构化将容许有效的数学公式检索 ,从而使问答系统、抄袭检测和其它自动化任务成为可能,它们在教育、科研和其它方面都有很多潜在的应用。
与普通文本相比,数学公式更不方便于输入。传统的输入设备如键盘是为单方向的字符串而设计的,虽然符号间的平面位置关系可以用 TeX 或 MathML 之类的代码表示,但用计算机语言表达数学公式对新手而言非常不友好,因为他们不仅要另外学习一门语言和记忆一系列命令,还要与令人困惑的错误打交道。另一方面,用图形化的公式编辑器输入数学公式对老手而言效率太低,因为重复地从工具箱中选取结构元素和符号费时失事。
既然人们已经习惯了在纸上或黑板上书写数学公式,用相同的方式向计算机输入数学公式就是最理想的。识别系统的目标就是把手写的数学公式转化为方便机器处理的语法树。手写识别又分为联机识别和脱机识别,两者间的区别在于联机识别系统接受动态笔迹为输入,而脱机识别则接受位图为输入。联机识别容许人们通过在触摸设备上书写或拖动鼠标来输入数学公式,适合用于记笔记或与计算机代数系统交互。脱机识别则容许人们录入图片中的数学公式,适合用于电子化手稿的扫描版或者黑板的照片。
值得一提的是,数学公式是一类有代表性的二维记号,可以被用来识别手写数学公式的技术也可能可以被用于识别手写的表格、化学结构式、乐谱、电路图、流程图等等,又或是对手写文档进行版面分析。这些任务和数学公式识别同样受符号切分、符号识别和结构分析问题困扰,也和手写数学公式识别一样有实际的用途。
为什么会想到笔划提取
通过简单地把笔迹渲染为图片,我们可以轻易地把联机识别问题转化为脱机识别问题。也就是说,给定一个脱机识别系统,我们总可以构造一个和它一样准确的联机识别系统。反过来,如果能够从位图中恢复笔迹信息,联机识别系统也能被用于脱机识别,这样做有以下潜在好处:
- 提高准确率。联机识别的准确率一般比脱机识别高,而且笔划提取容许同时用联机和脱机数据进行训练。
- 加快识别和降低内存占用。基于卷积神经网络的脱机识别是计算密集的,往往需要GPU等硬件来加速。
- 降低安装包大小。对于需要同时支持联机与脱机识别的应用,基于笔划提取时只需部署一套模型就能完成两种任务。
- 减低维护成本。由于联机与脱机识别有一定的相似性,平行地分别开发两套识别系统难免有重复劳动的成分。
如何基于笔划提取做脱机识别
首先,我们需要一个笔划提取器来把位图转换为笔划序列,这样就可以对提取出的笔划调用联机识别系统了。如果笔划提取完全准确,脱机识别就能做到和联机识别一样准确。虽然这不太容易实现,但在笔划提取大致准确时,已经足以构造准确性有竞争力的脱机识别系统。以下这个笔划提取器纵使不完美,但它的每一步都是有用的。
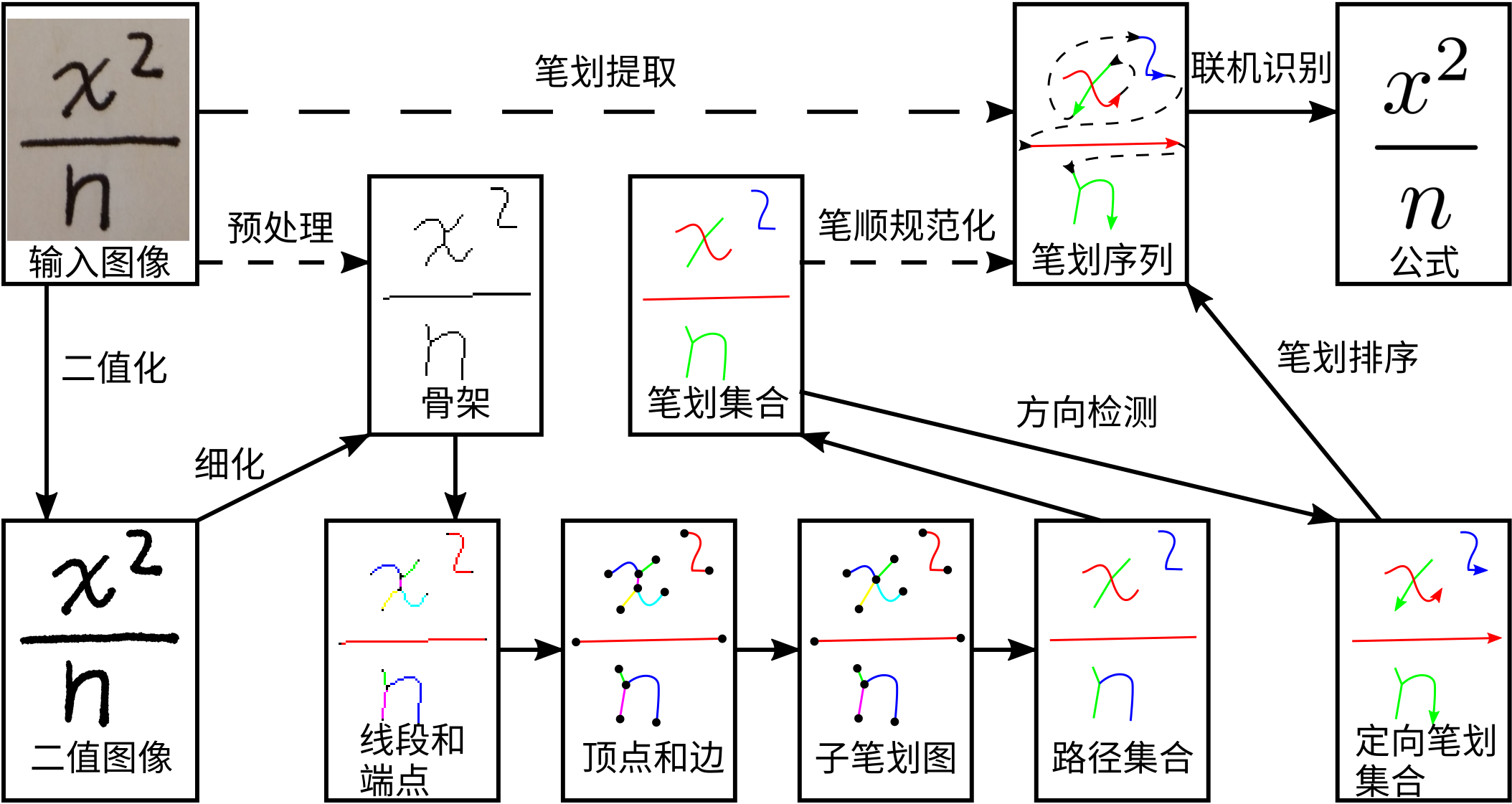
其次,在可行的情况下用提取出的笔划代替原始笔划去重新训练所基于的联机手写数学公式识别系统,从而避免笔划提取器的单点故障问题。借助这做法有望得到准确性与联机识别系统相近的脱机识别系统。这还使得我们可以利用脱机手写数学公式和印刷体数学公式来训练联机手写数学公式识别系统,有利于增大训练集。
如何利用不完美的识别系统
目前即使最好的联机识别系统的准确率也只有80%,也就是说写几条公式就很可能会遇到误识的情况,因此应用必须考虑这种情况。
- 对于要求高准确性的场合,例如作为计算机代数系统的输入时,需要设计方便用户高效地修正数学公式的界面。以下是一些可能可提高公式编辑器的可用性的思路:
- 提供多个备选公式供用户选取,因为识别系统的前k准确率往往明显比前1准确率高;
- 提供修改单个符号的操作,因为很多情况下识别结果结构正确而只是少数符号错了;
- 呈现输入笔划与输出符号间的对应关系,让用户更容易地发现错误;
- 整合键盘、鼠标和手势等输入方式,让用户用最熟悉的方式修正结果。
- 对于其它场合,例如数学公式检索,少量的识别错误往往不太影响最终结果,而且存在一些技术手段进一步限制这种影响:
- 利用多个候选识别结果去扩展查询,因为识别系统的前k准确率往往明显比前1准确率高;
- 利用错误感知的相似性度量,因为识别系统一般有一些常见的混淆模式。
全文
如欲了解更多细节,请参阅以下文献:
- Stroke Extraction for Offline Handwritten Mathematical Expression Recognition是一篇正式发表的英文学术论文
- 《基于笔划提取的脱机手写数学公式识别研究》是一份更详细但非正式的中文技术报告